# 数据增强——Embedding Mixup
# 方法介绍
Mixup是一种简单有效的embedding数据增强方法,论文的核心公式为
其中、和、是从训练集随机选择,取值为分布,范围0~1
Mixup的原理很简单,就是通过这种混合数据的方式增强模型的泛化性
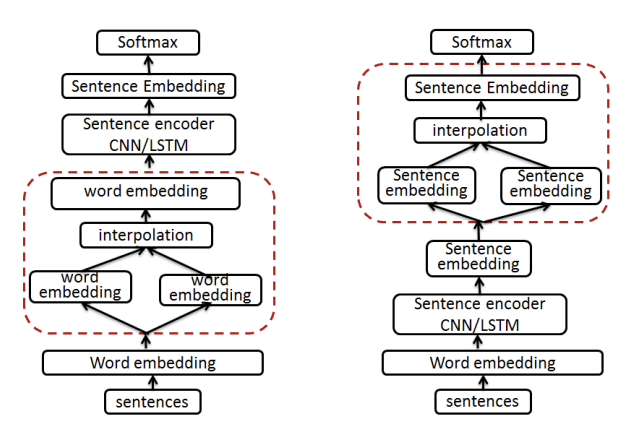
在NLP上的实践,包括word、sentence、encoder的mixup
class MyBert(nn.Module):
def __init__(self):
self.bert = BertModel.from_pretrained(self.bert_path, local_files_only=True)
pass
def forward(self):
pass
# 两个batch经过模型cls最终输出后的结果mixup
def forward_sentence_mixup(self, batch1, batch2, lam):
logs1 = self.forward(**batch1)
logs2 = self.forward(**batch2)
y = lam*logs1 + (1-lam)*logs2
return y
# 两个batch经过模型encoder输出后的结果mixup
def forward_encoder_mixup(self, batch1, batch2, lam):
out_pool1 = self.bert(**batch1)[1]
out_pool2 = self.bert(**batch2)[1]
pooled_output = lam * out_pool1 + (1.0-lam) * out_pool2
y = self.fc(pooled_output)
return
具体训练代码:
https://github.com/lianyongxing/text-classification-nlp-pytorch/blob/main/train/train_mixup.py
# References
[1]. mixup: BEYOND EMPIRICAL RISK MINIMIZATION
[2]. Augmenting Data with Mixup for Sentence Classification: An Empirical Study