# Adversarial Discriminative Domain Adaptation
# 理论基础
深度学习训练的一个假设是训练集和测试集是相同分布的,因此模型经过训练集训练后,往往在测试集上也会达到比较好的效果(比如将训练集按比例划分为训练、测试部分);但是实际中,测试集和训练集往往是不同分布的,因此在测试集上的效果会大打折扣;
理想的情况下,feature extractor提取的特征应该是高度抽象并且固定的,而后续的classifier负责根据feature判断目标类别,此时feature extractor和classifer应该是更通用的,而不随训练数据和测试数据分布不同产生改变,在训练数据训练后的model,可以直接应用在目标数据上,获得近似相同的效果
域自适应(domain adaption)就是为了解决这种问题,其核心思想为:将source和target的数据映射到相同分布的空间上,这样两者的数据差异就会减小,从而当成同一个数据集
# 域自适应对抗训练
域自适应对抗训练就是一种将source和target的数据分布拉近的方式,主要包括以下几个步骤
- 定义源域和目标域,分别有各自的encoder进行特征提取,分别有各自的classifer
- 目标为:将各自encoder提取的特征尽可能接近,从而source学习得到的classifer可以直接作用于target上
- 由于源域数据存在label,因此首先训练source encoder和classifier
- 通过对抗的方法,同时输入source和target数据,训练作用于目标域的encoder和一个classifier(discriminator,用于判别输入来自source还是target,将判别器效果达到最优)
- 判别器达到最优后,按住其不动,输入target数据训练encoder,让判别器尽量失误,此时target encoder逐渐趋于source encoder
- 使用目标域的encoder和源域的classifer进行最终类别的判定
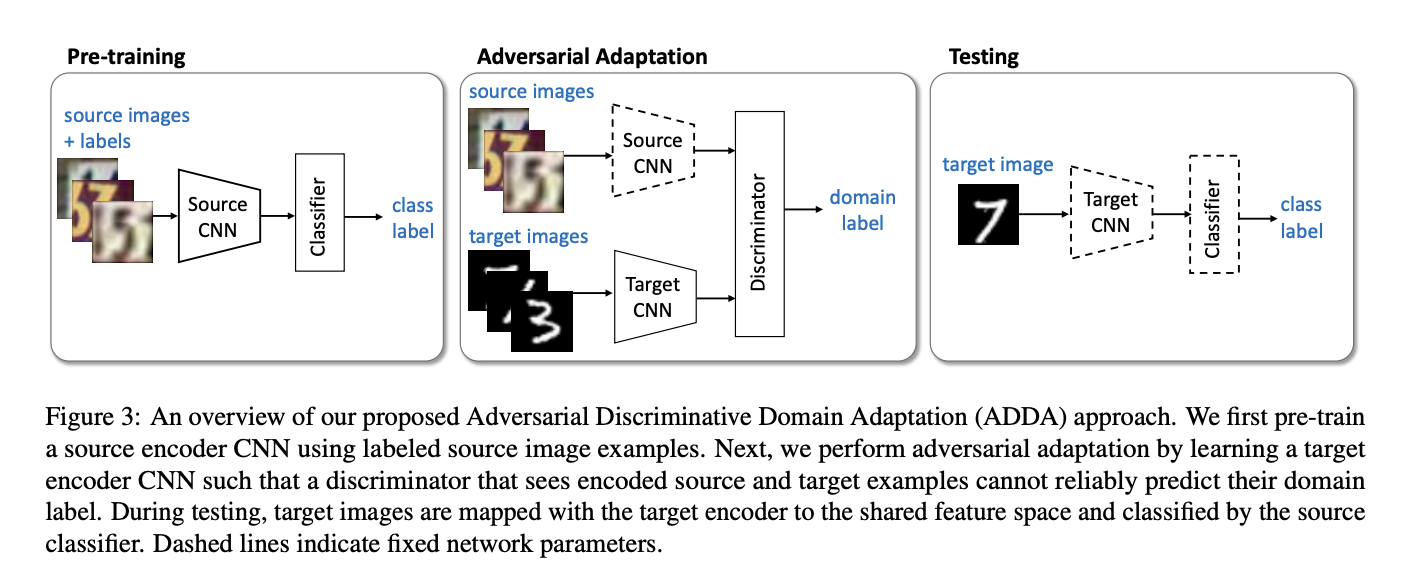
其中,虚线框代表参数固定,实线框代表参数学习
# 1. pre-training
# 正常根据source data训练模型
# 2. adversaial adaption
def train_tgt(src_encoder, tgt_encoder, discriminator,
src_data_loader, tgt_data_loader):
"""Train encoder for target domain."""
########################################
# 1. 初始化tgt_encoder 和 discriminator #
########################################
# set train state for Dropout and BN layers
tgt_encoder.train() # 最初使用src_encoder的参数初始化tgt_encoder
discriminator.train()
# setup criterion and optimizer
criterion = nn.CrossEntropyLoss() # discriminator的loss
optimizer_tgt = optim.Adam(tgt_encoder.parameters(),lr=1e-4,betas=(0.5, 0.9))
optimizer_discriminator = optim.Adam(discriminator.parameters(),lr=1e-4,betas=(0.5, 0.9))
len_data_loader = min(len(src_data_loader), len(tgt_data_loader))
################################
# 2. 对抗训练 && 训练tgt encoder #
################################
for epoch in range(10):
# zip source and target data pair
data_zip = enumerate(zip(src_data_loader, tgt_data_loader))
for step, ((images_src, _), (images_tgt, _)) in data_zip:
##########################
# 2.1 训练discriminator #
##########################
# make images variable
images_src = make_variable(images_src)
images_tgt = make_variable(images_tgt)
# zero gradients for optimizer
optimizer_discriminator.zero_grad()
# 将不同encoder提取的feature混合,一起输入discriminator,使其达到最优
feat_src = src_encoder(images_src)
feat_tgt = tgt_encoder(images_tgt)
feat_concat = torch.cat((feat_src, feat_tgt), 0)
# predict on discriminator
pred_concat = discriminator(feat_concat.detach())
# prepare real and fake label
label_src = make_variable(torch.ones(feat_src.size(0)).long())
label_tgt = make_variable(torch.zeros(feat_tgt.size(0)).long())
label_concat = torch.cat((label_src, label_tgt), 0)
# compute loss for discriminator
loss_discriminator = criterion(pred_concat, label_concat)
loss_discriminator.backward()
# optimize critic
optimizer_discriminator.step()
# acc越高,代表discriminator效果更好
pred_cls = torch.squeeze(pred_concat.max(1)[1])
acc = (pred_cls == label_concat).float().mean()
##############################
# 2.2 对target encoder进行训练 #
##############################
# zero gradients for optimizer
optimizer_discriminator.zero_grad()
optimizer_tgt.zero_grad()
# extract and target features
feat_tgt = tgt_encoder(images_tgt)
# predict on discriminator 单独输入tgt的特征
pred_tgt = discriminator(feat_tgt)
# prepare fake labels
# 与一起输入时的label相反,对抗训练
label_tgt = make_variable(torch.ones(feat_tgt.size(0)).long())
# compute loss for target encoder
# 目标是让discriminator判断失误,从而训练tgt encoder
loss_tgt = criterion(pred_tgt, label_tgt)
loss_tgt.backward()
# optimize target encoder
optimizer_tgt.step()
#######################
# 2.3 打印结果 #
#######################
if ((step + 1) % params.log_step == 0):
print("Epoch [{}/{}] Step [{}/{}]:"
"d_loss={:.5f} g_loss={:.5f} acc={:.5f}"
.format(epoch + 1,
params.num_epochs,
step + 1,
len_data_loader,
loss_discriminator.item(),
loss_tgt.item(),
acc.item()))
#############################
# 2.4 save model parameters #
#############################
if ((epoch + 1) % params.save_step == 0):
torch.save(discriminator.state_dict(), os.path.join(
params.model_root,
"ADDA-discriminator-{}.pt".format(epoch + 1)))
torch.save(tgt_encoder.state_dict(), os.path.join(
params.model_root,
"ADDA-target-encoder-{}.pt".format(epoch + 1)))
torch.save(discriminator.state_dict(), os.path.join(
params.model_root,
"ADDA-discriminator-final.pt"))
torch.save(tgt_encoder.state_dict(), os.path.join(
params.model_root,
"ADDA-target-encoder-final.pt"))
return tgt_encoder
# 注意
以上训练过程,代表了GAN交替训练的两个过程:
- 拿一批真假混合的数据训练判别器discriminator,让其达到最佳,可以区分输入来源;
- 固定判别器discriminator,输入假数据,给fake label,让判别器判别错误,从而训练encoder,使其达到最优,当判别器效果最好的时候都判别错误,意味着真假数据的encoder已经相同