# 深度网络演进

最早的深度网络,仅包含各个普通的层的CNN,卷积层,激活函数,池化层,全连接层
# AlexNet

Alexnet是2012的ISLVRC冠军,准确率由70%提高到80%左右,使用GPU训练
# 主要亮点
- 使用GPU训练
- 使用了Relu函数
- 使用了LRN局部响应归一化
- 在全连阶层使用dropout随机失活神经元,以减少过拟合
# VGG
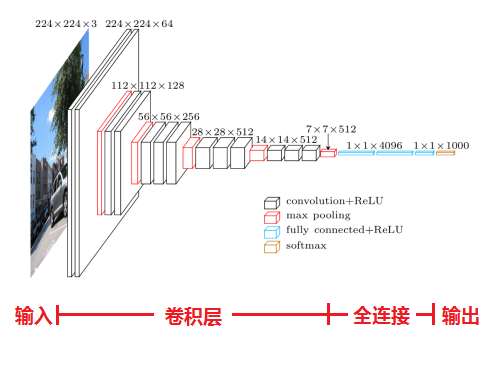
2014年推出,ImageNet获奖
网络中的亮点,通过堆叠多个3x3的卷积核来代替大尺度卷积核(减少所需的参数),从而使网络层次更深
可以使用堆叠2个3x3的卷积核来替代5x5的卷积核,堆叠3个3x3的卷积核来替代7x7的卷积核。(具有相同的感受野)
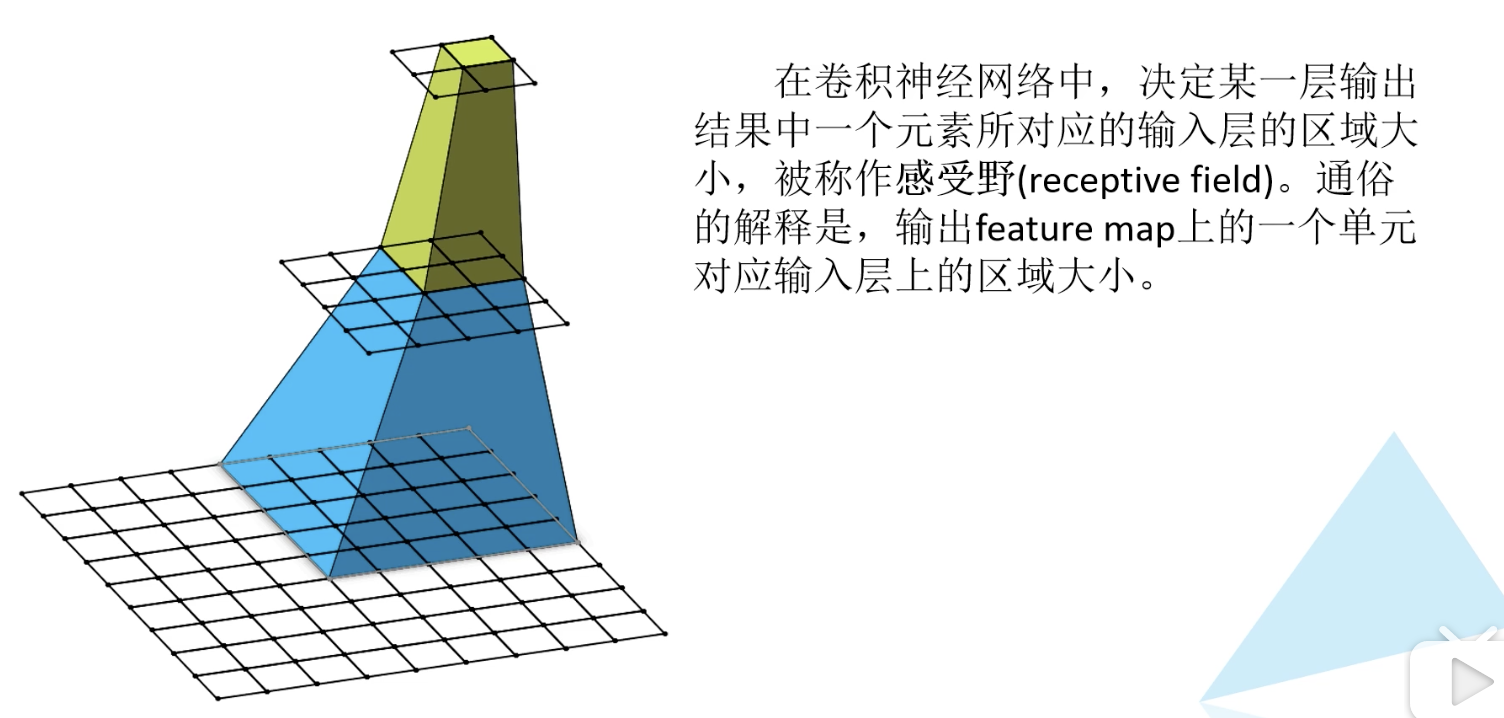
感受野计算公式:
第一层 1
第二层 (F(1)-1)*stride + ksize
第三层 (F(2)-1)*stride + ksize
第n层 (F(n-1)-1)*stride + ksize
感受野的概念
# GoogLeNet
- 引入了Inception结构
- 使用1x1卷积核进行降维以及映射处理
- 添加两个辅助分类器进行训练
- 丢弃全连接层,使用平均池化层(大大减少模型参数)
# Inception结构
初始的Inception结构

不同分支得到不同尺度的特征矩阵,每个分支得到的特征矩阵的高和宽必须相同(在深度上进行拼接)
添加了降维模块的Inception结构

使用1x1的卷积核进行降维,降维可以抽取特征点和主要特征
# 辅助分类器
在中间输出层接一个分类器,作为辅助分类,因此在训练的时候有3个loss
# ResNet
Resnet2015年提出,ImageNet第一名
网络亮点
- 超深的网络结构(突破1000层)
- 提出残差模块
- 使用batchnormal加速训练(丢弃dropout)
过深的网络
- 存在梯度消失和梯度爆炸(梯度剪切/正则、激活函数、BN、预训练微调,残差网络,LSTM)
- 退化问题
# 残差模块
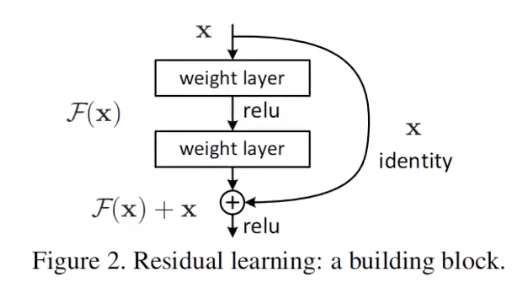
主分支与shortcut输出特征矩阵的shape必须相同,因此如果是虚线的话,就是先做一个变维操作,再进行结合。
残差一半比较小,学习残差难度小一点
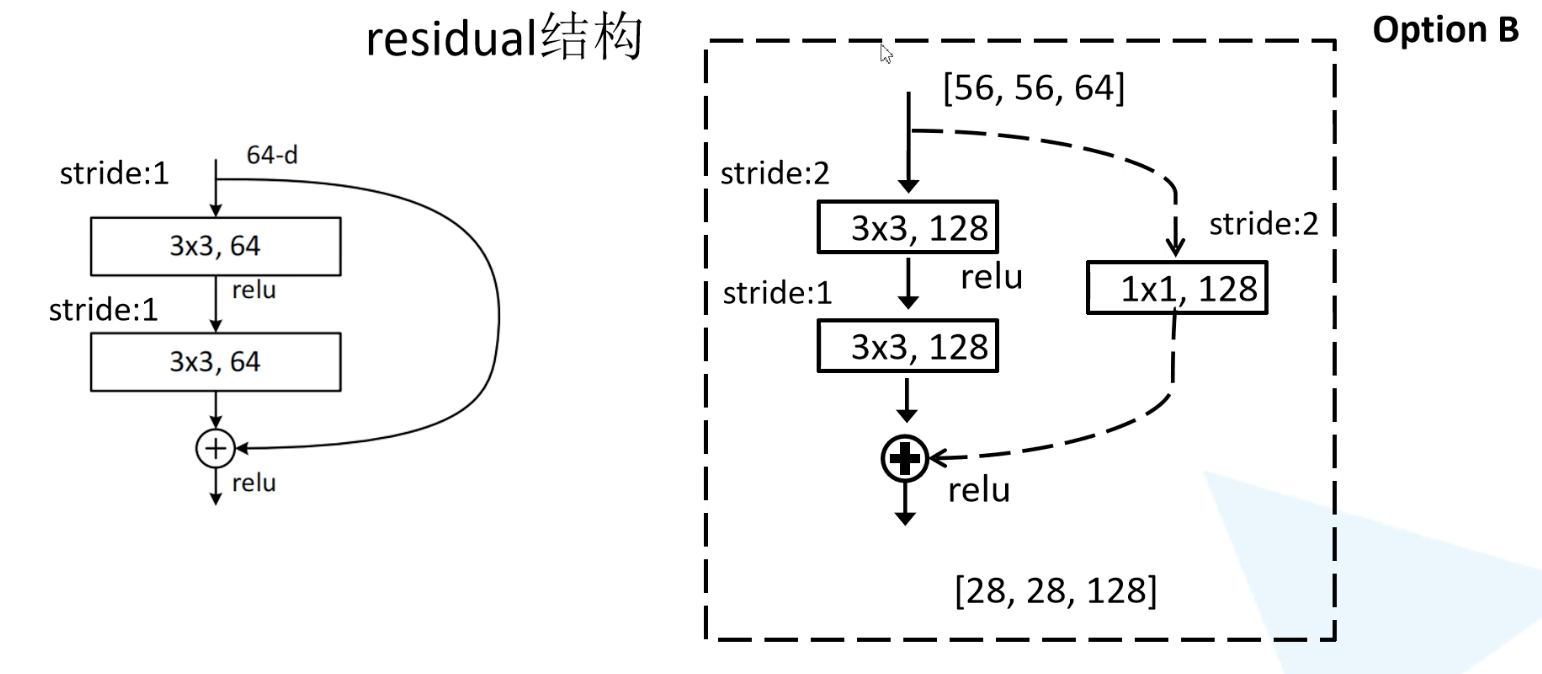
这个操作可以使得低维的信息为高维的信息做一个补充,并且防止梯度消失
# BatchNorm
在图像输入时,一般会对图像进行标准化处理,这样能加速网络的收敛,对于第一个conv层,输入是满足某个分布的特征矩阵,但其输出就变了,作为下一个conv的输入时,不满足某个分布规律了(这里指的是整个训练样本集对应的feature map的数据要满足的分布规律)。而batchnorm就是使feature map满足均值为0,方差为1的分布律。

对于一批数据,计算均值和方差,然后将数据进行归一化,归一化后再用两个参数进行线性调节,因为均值为0,方差为1的数据的效果不一定是最好的,这两个参数是通过反向传播进行学习得到的。
# BN需要注意的问题
- 训练时将traing设置为True,验证时设置为False
- batchsize设置的尽可能大,在小的时候表现不好,设置大的求的的均值和方差接近整个训练集的均值和方差
- 论文中建议将BN层放在Conv和激活函数之间,且卷积层不要使用bias,因为没有用(调整后的值和调整前的值一样)
因为输出如果有bias,则归一化的时候减去均值时,也会有bias,两者抵消,而方差相同,因此输出相同。
# MobileNet
mobilenet是2017年提出的,专注于移动端或者嵌入式设备中的轻量CNN网络,准确率小幅度降低的情况下大大减少了模型参数的运算量
网络亮点
- Depthwise Convolution(大大减少运算量和参数数量)DW卷积
- 增加超参数 控制卷积核的个数的参数alpha,控制输入图像大小的beta
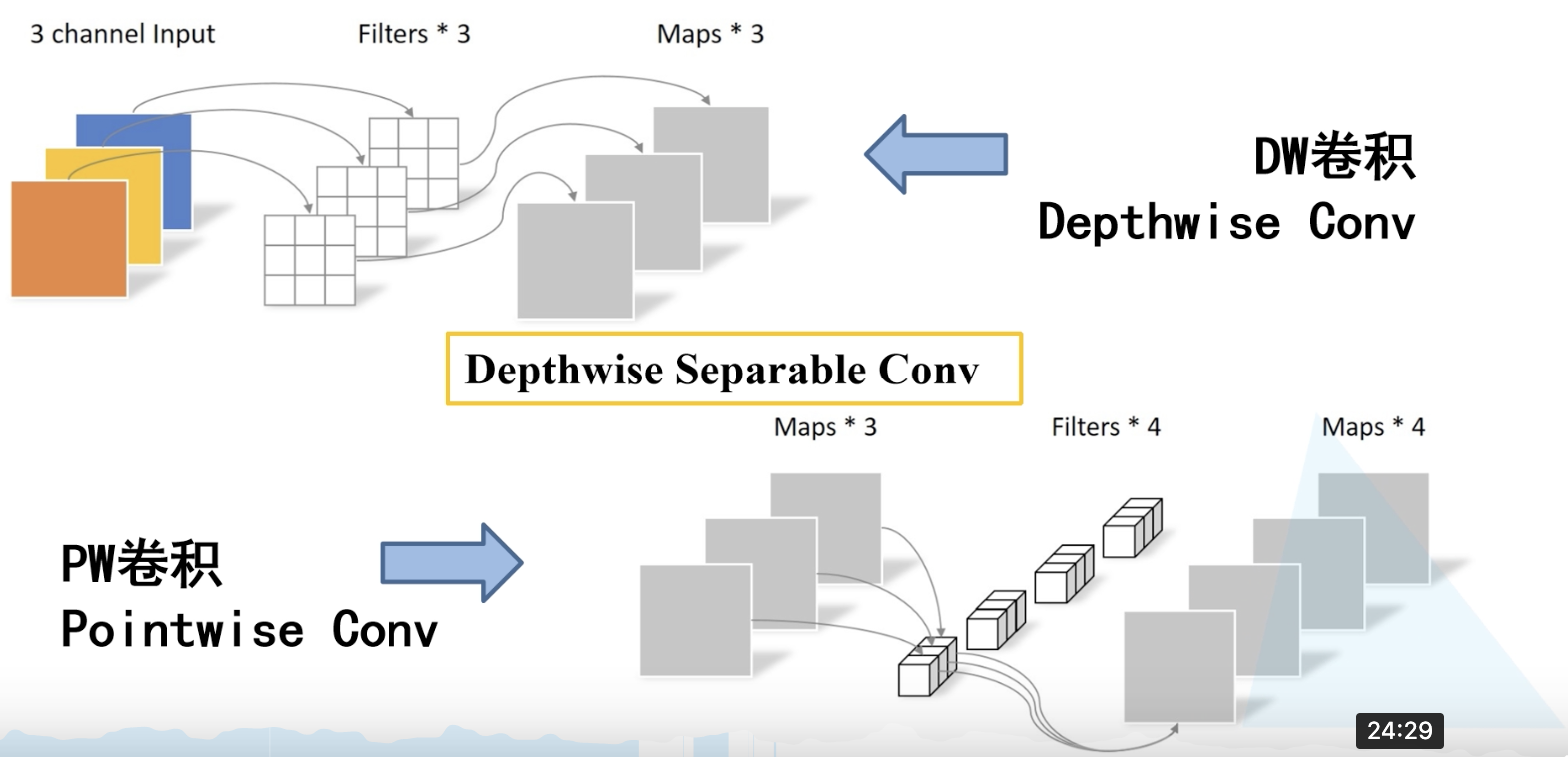
# DW卷积(Depthwise Conv)
卷积核channel = 1(每个卷积核负责1个channel )
输入特征矩阵channel = 卷积核个数 = 输出特征矩阵channel
# 深度可分的卷积(Depthwise Separable Conv)
由DW卷积(DepthWise)和PW卷积(PointsWise)组成
PW卷积就是普通卷积,只不过尺寸是1x1
# MobileNet v1
v1版本集成了DW卷积和PW卷积,引入两个参数控制卷积核的个数,控制输入图片的size,虽然在精度上有一点下降,但是大大降低了模型参数和计算量,但在实际训练的时候,发现depthwise部分卷积核会被废掉,即卷积核参数大部分为0,这个在v2版本进行了改善
# MobileNet v2
相比v1准确率更高,模型更小。
亮点主要有两个:
- Inverted Residual block(倒残差结构)
- Linear Bottlenecks
回顾:残差结构将输入通过1x1的卷积核,降低输入特征的channel,然后正常卷积,最后再通过一个1x1的卷积核扩充channnl,即步骤包括1x1降维、卷积、1x1升维。
A. 倒残差结构
先通过一个1x1的卷积核实现channel升维,再通过3x3的DW卷积,最后通过1x1的卷积核channel降维,正好跟残差结构是相反的,因此叫倒残差结构。需要注意的是,在普通残差网络中,激活函数为RELU,而在倒残差结构中,使用的激活函数为RELU6

B. linear Bottlenecks
对于倒残差结构中最后一个1x1的卷积层,采用了线性激活函数,而非RELU,原论文中,RELU对低维特征信息造成较大损失。
作者在论文中做了一个实验,用一个单通道的图片作为输入,然后用多层矩阵作卷积进行特征提取,提取高维特征后,用RELU输出,然后再用进行反变换,企图得到最初的输入。当提取2、3层时,发现做反变换后,得到的输出图像相对于输入图像有很大的缺失,而提取到10层以上的时候,才可以相对完整的还原出原始图像,因此觉得RELU对低维的信息会产生损失。而由于倒残差结构两边细,中间粗的结构,输出的是一个低维的信息,因此不使用RELU激活函数,而使用线性激活函数。

注意:在倒残差结构中,只有输入stride为1,而且输入特征矩阵和输出特征矩阵shape相等的时候才有shortcut连接
# 迁移学习
