# 进程调度
在合适的时候以一定的策略选择一个就绪的进程进行
# 目标
- 响应速度尽可能快
- 进程处理时间尽可能短
- 系统吞吐量尽可能大
- 资源利用率尽可能高
- 对进程要公平
- 避免饥饿
- 避免死锁
# 一些概念
- 周转时间:进程提交给计算机到最终完成的时间(说明了进程在系统中停留时间的长短
)
:进程提交时间
:进程完成时间
- 平均周转时间:一堆进程在CPU中停留的平均时间(平均周转时间越短,说明系统吞吐量越大,资源利用率越高
)
- 带权周转时间
:进程的周转时间
:进程的运行时间(run)
表明进程在系统中相对停留时间
# 典型的调度算法
# 先来先服务(First Come First Serve)
# 思路
先进入系统的先执行
# 特点
- 容易实现,效率不高
- 只考虑等待时间,而不考虑执行时间,因此一个晚来的短时间作业可能要等很长时间才能被执行,不利于短作业
# 短作业优先调度(Short Job First)
# 思路
参考运行时间,运行时间短的早执行
# 特点
- 易于实现,效率不高
- 忽视了等待时间,一个早来但是很长的作业将会在很长时间得不到调度,易出现资源“饥饿”的现象
# 响应比高者优先调度
# 思路
按照响应时间和运行时间的比值大小排队,响应比高的先运行
- 如果作业等待时间相同,则运行时间越短的作业,响应比越高,越容易被调度,有利于短作业。
- 如果运行时间相同,则等待时间越长的作业,响应比越高,越容易被调度,有利于长作业。
- 对于运行时间长的作业,其优先级可以随等待时间的增加而提高,当等待足够久的时候,也有可能获得CPU。
# 优先数调度
# 思路
根据优先数,把CPU分配给最高的进程
进程优先数 = 静态优先数(创建时确定,整个进程运行期间不可修改) + 动态优先数(在进程运行期间可以改变)
# 循环轮转调度
# 思路
把所有就绪进程按照先入先出的原则排成队列。新进程加到末尾,进程以时间片q为单位轮流使用CPU。刚刚运行一个时间片的进程排到队列末尾,等候下一轮运行。
队列逻辑上是环形的。
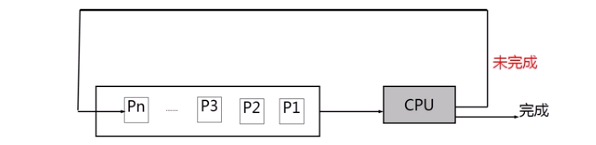
# 特点
- 公平
- 每个进程等待(n-1)*q的时间就可以重新获得CPU
# 时间片
如果时间片q太大,则交互性差,甚至退化为FCFS算法;如果时间片q太小,则进程切换频繁,系统开销增大。可以改变时间片的大小或者组织多个时间片不同的队列进行改进。
# Linux进程调度
# 进程划分
为了方便调度,将进程分为普通进程和实时进程
普通进程:采用动态优先级来调度,调度程序周期性地修改优先级(避免饥饿)
实时进程:采用静态优先级调度,由用户预先指定,之后不会改变
# 优先级
- 静态优先级
- 进程创建时指定或由用户修改
- 动态优先级
- 在进程运行期间可以按照调度策略改变
- 普通进程采用动态优先级,由调度程序计算
- 只要进程占用CPU,优先级就随时间流逝而不断减小
- task_struct的counter表示动态优先级
# 调度策略
- 实时进程
- SCHED_FIFO(先进先出):当前实时进程一直占用CPU直至退出或阻塞或被抢占,阻塞后再就绪时被添加到同优先级队列的末尾
- SCHED_RR(时间片轮转):与其他实时进程以Round-Robin方式共同使用CPU,确保同优先级的多个进程共享CPU
- 普通进程
- SCHED_OTHER(动态优先级)
- counter成员表示动态优先级
当系统调用sched_setscheduler()改变调度策略,实时进程的子孙进程也是实时进程。
# 进程调度的依据
task_struct中的几个成员变量
policy:表示进程的调度策略,用来区分普通进程和实时进程
priority:表示静态优先级
rt_priority:表示实时进程的优先级
counter:表示进程连续运行的时间
- counter值的含义:表示进程连续运行的时间,单位是时钟滴答tick数。比如时钟中断周期tick为10ms,如果counter=60,则能持续运行600ms。高优先级的进程一般counter较大。一般把counter看作动态优先级。
- counter的初值和priority有关:普通进程创建时counter的初值为priority的值
- counter的改变:时钟中断tick时,当前进程的counter减一,知道0被阻塞。
- 创建子进程counter从父进程时间片counter中继承一半,防止用户无限制创建后代长期占用CPU资源。
# 调度时机
- 中断处理过程中直接调用schedule():
- 时钟中断、I\O中断,系统调用和异常
- 内核被动调度的情形
- 中断处理过程中返回用户态时直接调用schedule():
- 必须根据need_resched标记
- 内核线程可直接调用schedule()进行进程切换:
- 内核主动调度的情形
- 用户态进程只能通过陷入内核后在中断过程中被动的调用
- 必须根据need_resched标记
# 进程切换
# 概念
- 内核刮起当前CPU上的进程,并恢复之前挂起的某个进程
- 任务切换、上下文切换
- 与中断的上下文切换有区别,中断前后在同一进程的上下文当中,只是用户态到内核态执行
- 进程上下文包含了进程执行需要的所有信息
- 用户地址空间:程序代码、数据、用户堆栈
- 控制信息:进程描述符、内核堆栈等
- 硬件上下文
# 进程调度和切换的流程
schedule()函数
选择新进程
next = pick_next_task(rq,prev);//进程调度算法
调用宏context_switch(rq,prev,next);切换进程上下文
# prev:当前进程,next:被调度的新进程
# 调用switch_to切换上下文
switch_to(prev,next)
# 两个进程A、B切换的过程
- 正在运行用户态进程A
- 发生中断
- 保存current进程的cs:eip/esp/eflags(一些标志寄存器)到内核堆栈
- 从内核堆栈装入ISR中断服务例程的cs:eip(入口地址)和ss:esp(堆栈)
- SAVE_ALL //保存现场,已进入内核中断处理过程
- 中断处理过程中或中断返回前调用了schedule()
- 其中的switch_to做了进程上下文切换
- 运行用户态进程B(B曾经通过以上步骤被切换出去过,现在重新回到CPU中)
- RESTORE_ALL //恢复现场
- iret //中断返回 堆栈中弹出pop cs:eip/esp/eflags
- 继续运行用户态进程B