# Contrastive Learning
# 主要思想
对比学习属于自监督学习,不依赖标注数据,从数据中学习同类数据的相同特征,将其编码为抽象特征,对比学习的主要思想:只需要区分那些样本是一个类别,而不需要知道样本是什么,对比学习的目的是所有相似样本在特征空间的相邻区域,而不相似的样本在特征空间的不相邻区域。如何定义哪些样本相似,通过自定义任务来实现,比如定义样本只与自己本身相似。
核心任务为:对比样本和对比损失的设计
# CV和NLP中的实现
在CV中,SimCLR方法,对同一张图片,进行不同的增强,得到两个对比样本(都是由原图简单处理后得到),然后将相同图片得到的对比样本之间的(距离)loss拉近,不同图片的对比样本之间的loss拉远。
# SimCSE
而在NLP任务中,采用了相同思想的SimCSE方法,对每个句子的embedding做两次dropout作为对比样本,相同句子的向量作为正样本对,不同句子的对比样本作为负样本对,计算整体contrastive loss
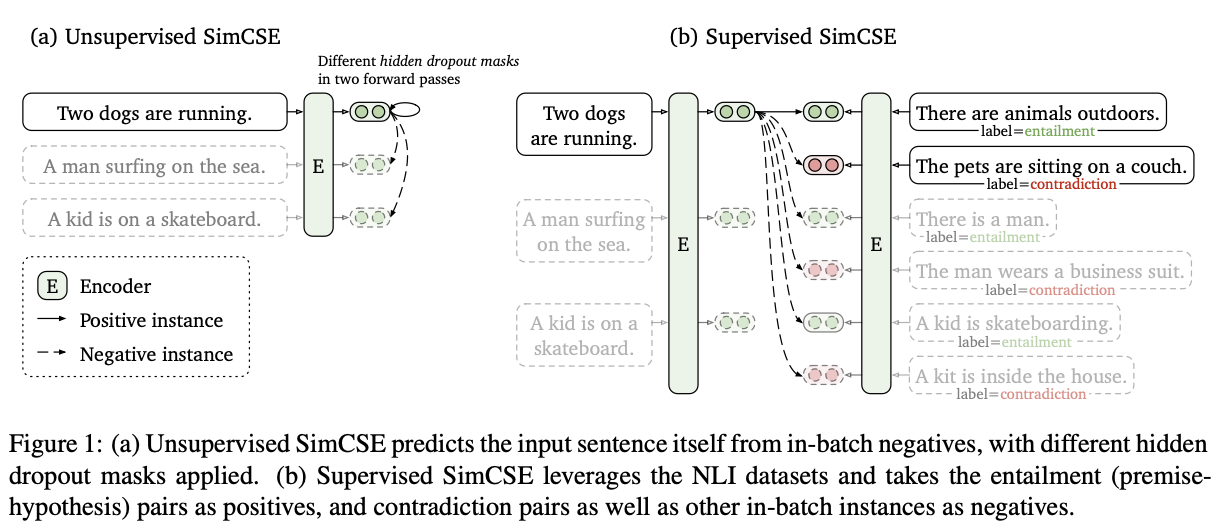
在SimCSE实际操作时,一共由n个句子,生成2n个对比样本,其中每个句子存在1个正样本,其余2n-1作为负样本,在计算loss时,拉近正样本的距离,拉远负样本的loss
SimCSE几个缺点:
- SIMCSE基于BERT预训练模型,因此对一个句子存在一个position embedding的长度信息编码,会带来一种影响,即长度相同的句子更近似,不同句子的长度不同,这会给模型带来误导:模型会自动认为相同或者相似长度的句子在语义上更相似
- 对比学习是在正负例对之间进行,理论上更多负例可能获得更多优质的对比,因此潜在的优化方向是利用更多负例对,使模型进行更精细的学习,而在simcse中,更大的batch效果往往会变差
SimCSE训练代码:待补充
# E-SimCSE
针对SimCSE的两个缺点,作者进行了两点改进
- 对于句子长度的影响,作者采用了一种样本增强的方法Word Repetition,即随机复制句子中的一些单词(期望在不改变语义的同时改变长度,而删除和替换都存在较大改变语义的可能)
- 更大的batch意味着占用更多gpu内存,一个优化方式是加入动量对比Momentum Contrast,通过维护一个队列,重用来自前一个mini-batch的embedding来扩展负例对:他将当前mini-batch的embedding加入队列,并将“最旧”的embedding出队列,由于队列中的数据随着batch不断更新,通过取其参数的移动平均来保持动量模型的更新,而不对其进行直接梯度更新,并且,作者在使用动量编码器时关闭了dropout,这可以缩小训练和预测之间的差距
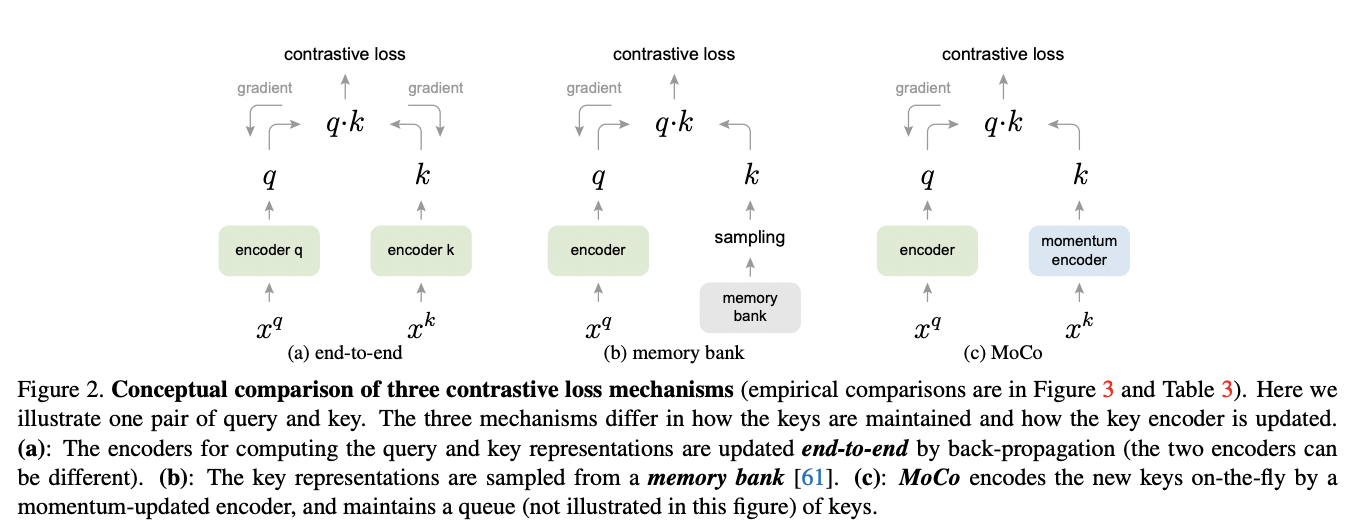
PS:其中Momentum Contrast是Kaiming再另一篇文章[4]里提出的
# References
[1]. SimCSE: Simple Contrastive Learning of Sentence Embeddings
[2]. A Simple Framework for Contrastive Learning of Visual Representations
[3]. ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
[4]. Momentum Contrast for Unsupervised Visual Representation Learning