# Transformer
# Embedding
# 对input进行表示
普通的表示为one-hot coding
# word embedding
one-hot表达结果稀疏,不能表达word与word之间的特征,因此对词进行embedding,用短向量表达word的属性
# Positional embedding
对每个word进行embedding作为input表达,但是这其中不包含句子中单词的位置信息。RNN可以在任何地方对同一个word使用一个相同的向量,是因为RNN是按顺序对句子进行处理,一次一个word,但是在transformer中,输入句子的word是同时处理的,没有考虑词的排序和位置信息
对此,加入了Positional embedding,position encoding和word embedding相加就可以得到embedding with position
有两种方式:
- 通过训练学习position encoding向量
2.通过公式计算position encoding向量,实验中效果与第一种近似,因此用第二种方法,优点不需要训练参数
计算公式为
相当于每个embedding的维度上,不同的位置都是周期变化的,然后随着embedding维度的增加,这个变化是越来越慢(每个维度都对应一个正弦曲线,这样可以让模型会更轻松的通过位置来学习)
# Encoder
encoder由6个相乘的Layer叠成,每个layer包含两个sub-layer,第一层是multi-head self-attention mechanism,第二个是simple、position wise fully connected feed-forward netwok
# Self-attention
一句话有5个单词,每个单词,用一个向量表示,比如512维
(啊:1x512),将其计算为三个256维的向量key、query、value
将每个字的query与所有字的key之间计算点积,因此获得了5个注意力得分,将其通过一个softmax归一化,然后将其分别乘以value,得到每个字最终的score,将其相加得到第一个字最终的输出
将一个字的embedding进行分割成h份,对每份用不同的W_q、W_k、W_v对得到多个key、query、value,其实就是多头的,multi-head self-attention
这里,Q和K的转置求点积,点积的几何意义是距离(两个模乘以夹角的余弦),当两个词向量越相似说明这个值越大(夹角越小),是一种距离的度量,最终得到的称为注意力矩阵。(实际上求点积之后,除以headsize的平方根,是因为防止headsize增大的时候,点积过大,因此进行缩放)
Tips:实际进行时,是用几个句子一起作为一个batch输入的,因此句子的长短是不一样的,所以需要按照最大长度的句子,为短句子补充padding,但是这样的话在进行softmax的时候,就会出现,注意力矩阵会有很多0
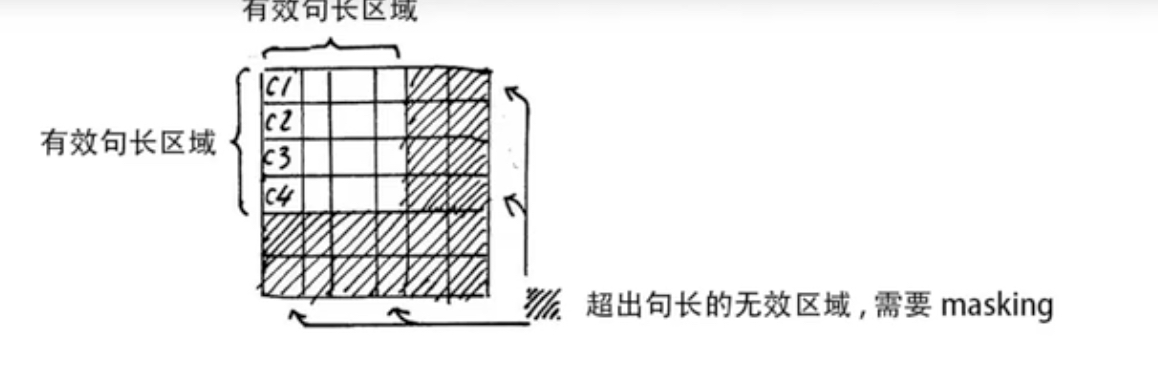
但是做完softmax,这些值都成为1了,因为,因此要给这些无效的区域加一个很大的偏置(很负的数),进行softmax后就变成了0
# Add and norm
Add是残差链接,norm是layer_normalization,这就是一个attention-block
每次输出是,之后的运算里,没经过一个模块的运算,都进行残差链接,从而梯度反向传播的时候可以走捷径。LayerNorm就是Batchnorm,
最后加上和,是为了弥补归一化的损失
# Feed-forward network
就是2个全连接层
# 架构图
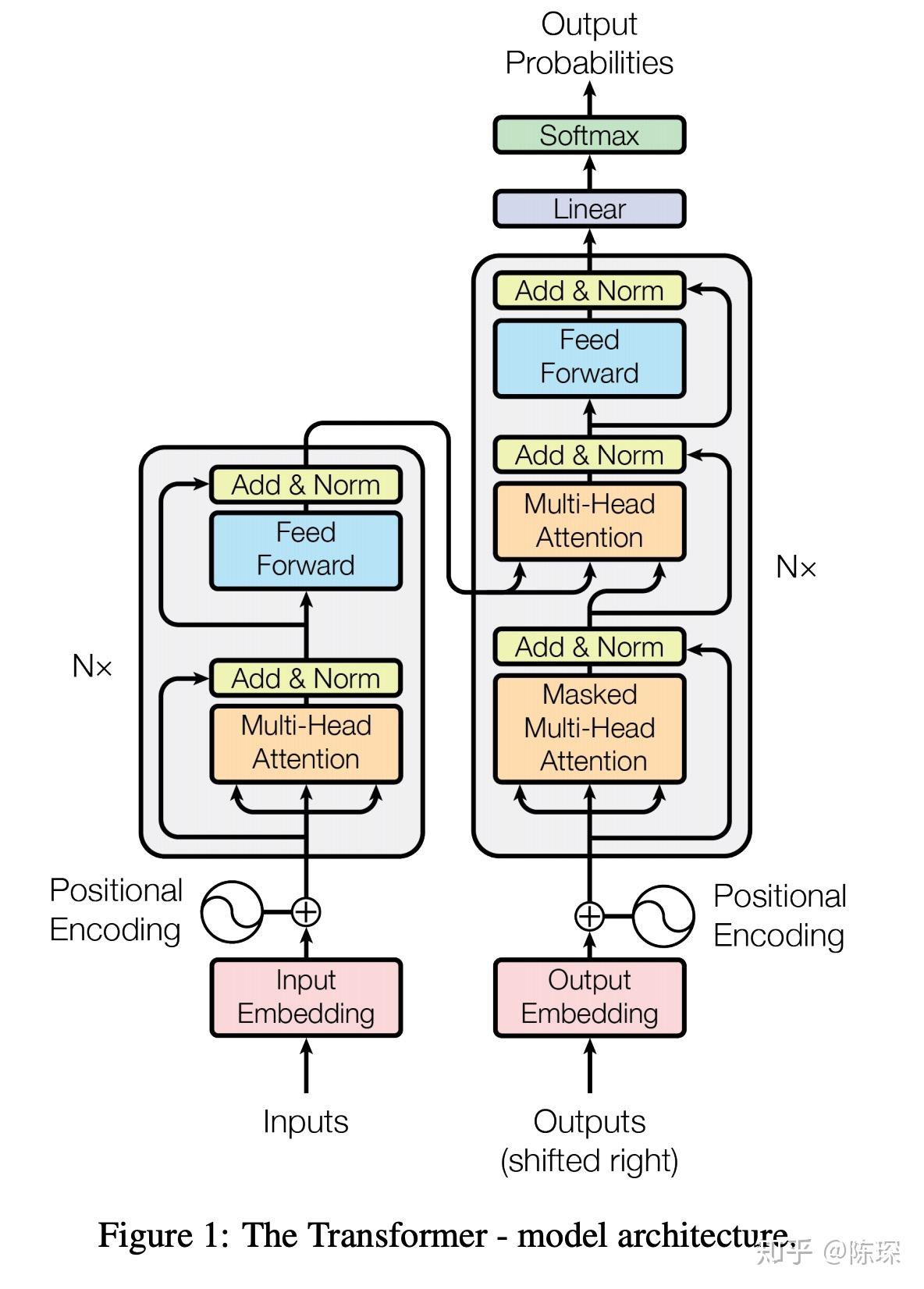
← 概述 FGSM→FGM→PGD →