优化器(Optimizer)
目的是为了使网络更快收敛
SGD
分批次进行训练,每次更新反向传播损失
wt+1=wt−αg(wt)
其中α为学习率
- 易受样本噪声影响:如果样本正确可以沿着梯度下降,但是如果样本错误,则可能沿着梯度反方向更新梯度
- 可能陷入局部最优解
SGD+Momentum
vt=ηvt−1+αg(wt)
wt+1=wt−vt
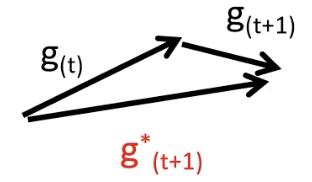
α为学习率,η为动量系数,除了计算当前梯度,还会加上一次的梯度方向,如图所示,可以抑制样本噪声的干扰
Adagrad优化器
st=st−1+g(wt)g(wt)
wt+1=wt−√st+ϵαg(wt)
α为学习率,ϵ为防止分母为零的小数,但是学习率下降太快,可能还没收敛就停止训练了
RMSProp优化器
st=ηst−1+(1−η)g(wt)g(wt)
wt+1=wt−√st+ϵαg(wt)
在上面的基础上,添加了一个控制衰减系数去调节,防止梯度下降过快。学习率变成了学习率处以二阶动量
Adam优化器
mt=β1mt−1+(1−β1)g(wt)
vt=β2vt−1+(1−β2)g(wt)g(wt)
mt′=1−β1tmt
vt′=1−β2tvt
wt+1=wt−√vt′+ϵαmt′
β1,β2都是控制衰减的系数,添加了一阶动量和二阶动量进行控制