# Faster RCNN合集
# R-CNN
# 算法流程
- 一张图像生成1k—2k个候选区域(使用selective search)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框的位置
# 候选区域生成
利用算法通过图像分割得到一些原始区域,然后使用合并策略讲这些区域合并,得到一个层次化的区域结构,这些结构就包含可能存在的物体
# 提取特征
将2000个候选区域缩放到227x227px,接着将候选区域输入实现训练好的网络,获取4096维的特征得到2000x4096维矩阵
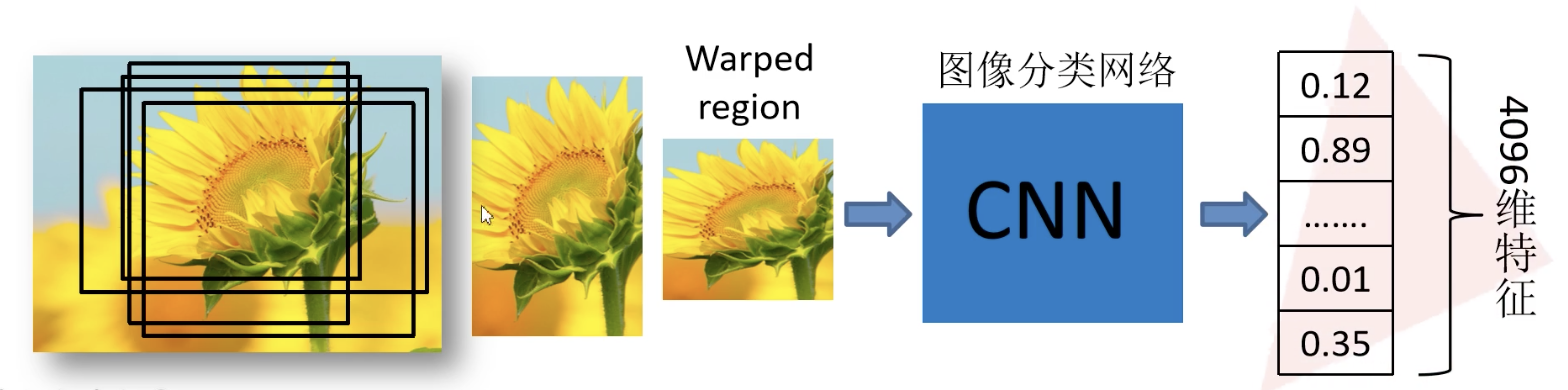
# 分类判别
针对每个类别都给一个SVM分类器,这样对于2000个候选区域,得到每个类的分类概率,比如20类,就得到2000x20的矩阵,第一列代表猫、第二列代表狗等等,按照每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即为该类得分最高的一些建议框
# 非极大值抑制
IOU(Interaction over Union,交并比),两个区域的交集比两个区域的并集。
对于每个类别,首先寻找得分最高的目标,计算其他目标与该目标的iou值,删除所有iou值大于给定阈值的目标(删除与这个目标重叠很大的那些候选框,因为与这个其实是一个目标)。然后把这个存起来,在剩下的目标中,再去寻找得分最高的目标,计算、删除,最终将所有框选出来
# 精细调整
对NMS处理后的剩余建议框进一步筛选,分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别修正后得分最高的boundingbox
比较简单的方法就是取预测值和GroundTrue的平均值进行修正
# 存在的问题
- 测试速度慢,selective search提取候选框要2s,一张图片中的候选框存在大量重叠,信息冗余(FastRCNN进行优化)
- 训练速度慢
- 训练所需空间大:对于SVM和boudingbox的回归,需要将每个候选框的特征写入磁盘,对于很深的网络,需要更多空间
# Fast RCNN
# 算法步骤
Fast RCNN主要分为3个步骤
- 一张图片生成1k-2k个候选区域
- 将图像(整个)输入CNN网络生成特征图,将SS算法生成的候选框投影到特征图上,获得相应的特征矩阵
- 每个特征矩阵通过ROI POOLING层缩放到7x7大小的特征图,接着将特征图展平,通过一系列全连接层得到预测结果
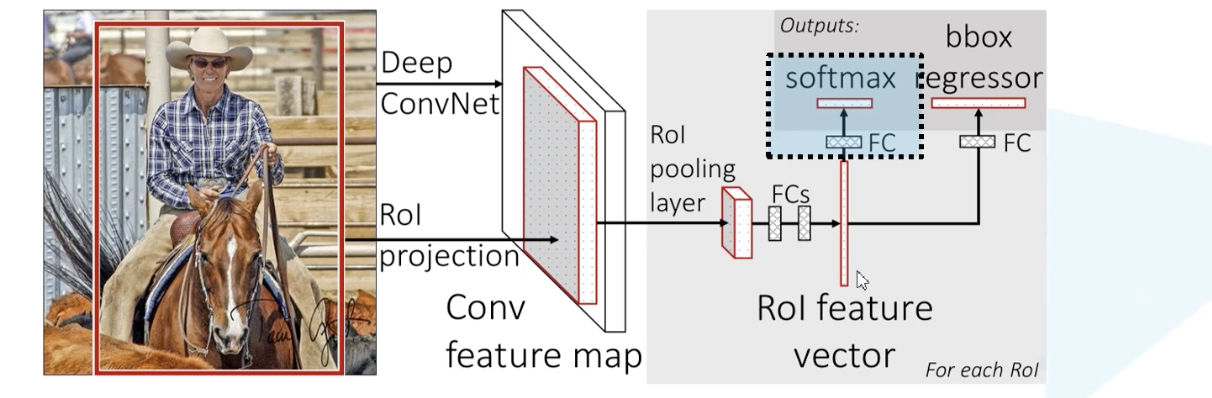
# 一次性计算整个图像的特征
RCNN对每个候选区域输入CNN网络提取特征,而FastRCNN将整个图像输入CNN网络中,得到一个大的特征图,然后根据原始图像的映射(SPPNET),从大特征图中提取相应的候选区域,这些候选区域的特征不需要再重复计算
并且FastRCNN并没有使用全部的SS算法提取的候选框,而是进行了采样,并且还做了一些负样本作为训练集
# ROI pooling layer
将ROI对应的特征区域划分为7x7的方框,然后在每个方块中进行maxpooling操作,这样就能得到一个7x7的特征图
# 分类器
将上一步的7x7的特征矩阵进行一个展平处理,通过一个全连接层,再分别通过两层全连接层(并行),一个进行softmax分类,一个进行bbox regression
# 边界框回归器
回归得到N+1个类别的可能边界框(N个类别,1个背景类别),然后跟GroudTrue的结果进行融合
# 损失函数
由于一个分类器,一个回归器,因此有两个损失,是一个Multi-task Loss

# Faster RCNN
# 算法步骤
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,并将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI Pooling层缩放为7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测效果
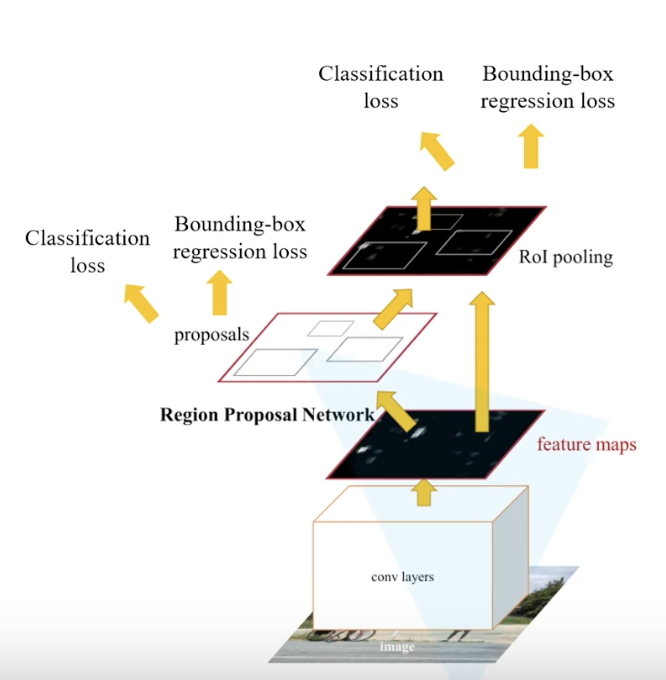
# RPN结构
RPN网络输入为原始图像的特征图,在特征图上通过3x3的滑动窗口,每滑到一个位置,就在原图上有3x3=9个anchor,就得到一个1维的向量(深度根据特征提取backbone channel数量),在这个向量的基础上通过两个全连接层生成2k个anchor score(目标概率,2k是针对k个anchorbox,对于每个anchor生成了2个概率,一个是背景的概率、一个是前景的概率)和4k coordinates(边界框参数,每个anchor生成4个边界框回归参数),计算出滑动窗口中心点对应原始图像的中心点,并计算出k个anchorboxed(不是proposal)
anchor:特征图中的一个中心点映射到原图中的一个点,然后以这个点在原图上画很多框框,这些就是anchor box
VGG的感受野:228,ZF的感受野:171
但是VGG可以在原图上定位更广的范围,作者在论文中的观点是,像人一样,看到一个目标的一小部分区域,也可以大致估计出整个目标的范围
对于一张1000x600x3的图像,经过网络提取后,尺寸大约60x40,因此大约有60x40x9(20k)个anchor,忽略跨越边界的anchor后,剩下约6k个anchor,对于RPN生成的候选框(proposal)之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IOU设置为0.7,这样每张图片只剩2k个候选框。在2k 个anchor最终采样256个anchor,包含正负样本用于训练。
# 训练过程
现在使用的网络是直接采用RPN loss + Fast RCNN loss联合训练的方法。
原论文中分别采用训练RPN以及FastRCNN的方法
- 使用Imagenet预训练模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数
- 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框训练FastRCNN网络参数
- 固定利用FastRCNN训练好的前置网络层参数,去微调RPN网络独有的卷积层以及全连接层参数
- 同样保持固定前置卷积网络层参数,去微调FastRCNN网络的全连接层参数。最后RPN网络与FastRCNN网络共享前置卷积网络层参数,构成一个统一的网络
# 存在的问题
对小目标检测效果较差
是在一个特征层上进行预测的,featuremap已经被抽象到比较高的层次上了,细节信息比较少,因此对小目标的检测比较差
模型大,检测速度较慢