# SSD
# 框架图
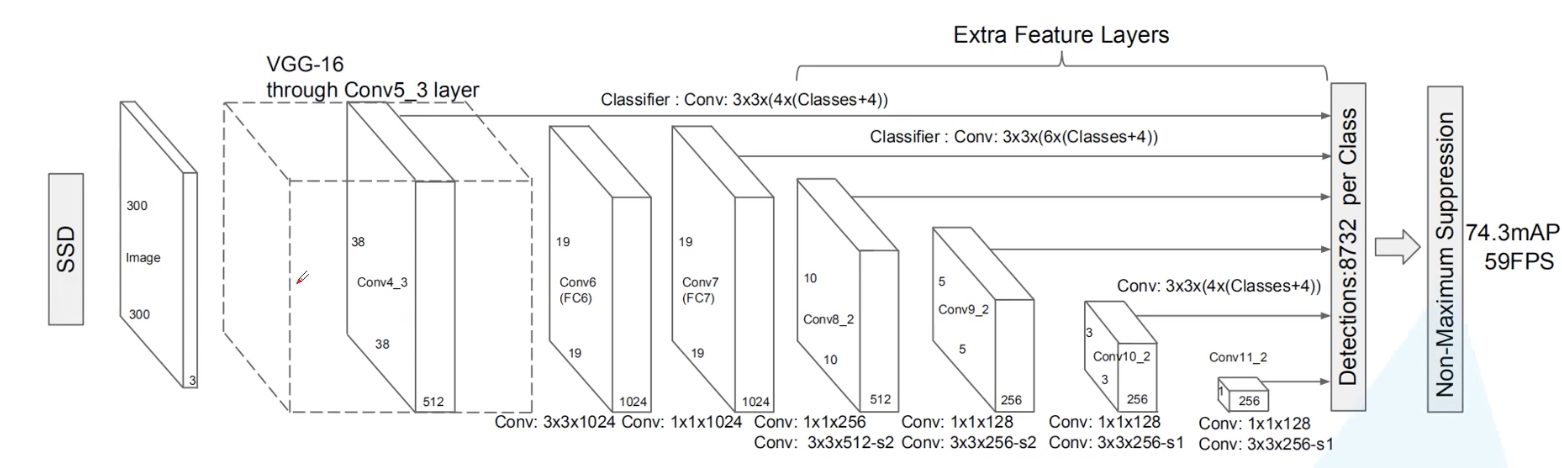
- 第一个特征层:300x300的图片输入网络,将图像输入到vgg16 backbone中,但是对vgg的部分进行了修改,尺寸38x38
- 第二个特征层:对第一个特征层做一个全连接,然后再卷积后作为第二个预测特征层,尺寸19x19
- 第三个特征层:对第二个特征层的输出再通过1x1的卷积层和3x3的卷积层作为第三个预测特征层,尺寸10x10
- 第四个特征层:同上得到第四个预测特征层,尺寸5x5
- 第五个特征层:同上得到第五个预测特征层,尺寸3x3
- 第六个特征层:同上得到第六个预测特征层,尺寸1x1
更低层的保留的特征是更多的,因此适合检测相对小的特征,而高层特征图往往丢失了很多细节信息,因此适合检测相对大的目标
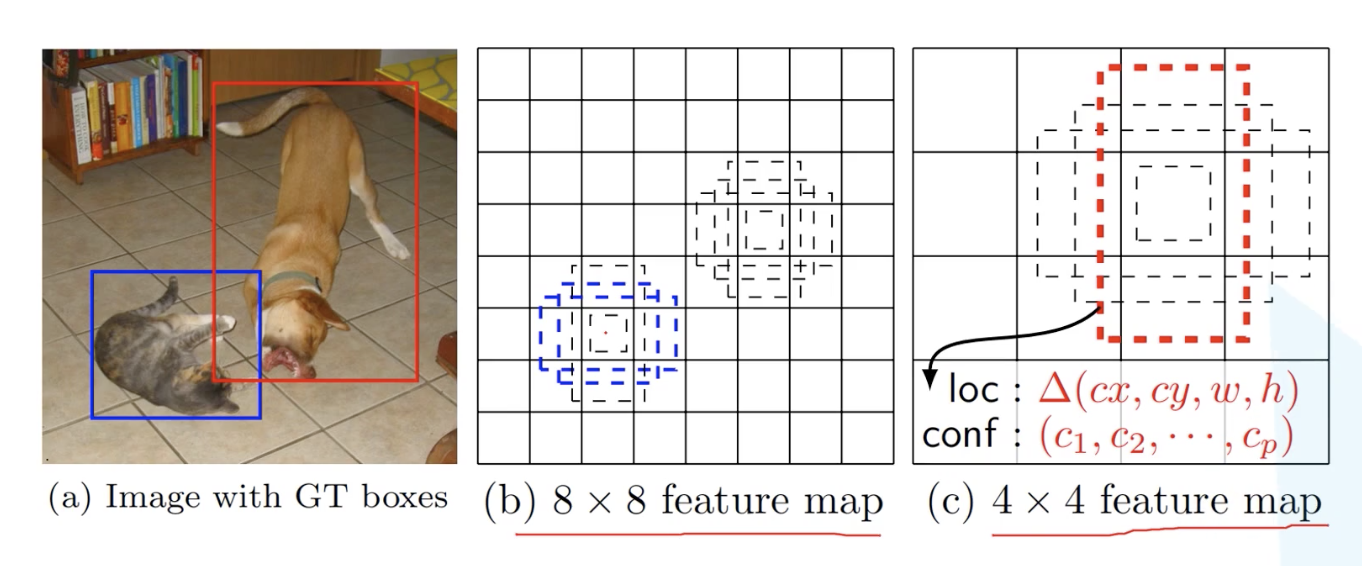
如图,b图中保留的特征更多,因此适合检测小目标;c图中保留信息较少,适合检测大目标,特征图上的框框就是Default box,类似于anchor box
在这6个特征层上分别预测不同尺度和比例的目标,最终通过极大值抑制,去除重叠目标
# Predictor
使用predictor在6个特征图上进行预测对于的特征层,直接用的卷积核进行实现,通过这个东西来生成分类得分和坐标偏移量(跟Faster rcnn的预测器近似一样)。对于特征图上每个位置,会生成k个defaultbox,对每个defaultbox都需要c个分类类别和4个坐标偏移量,因此需要(c+4)k个卷积核来进行预测,defaultbox生成8742个,但是在训练
# 正负样本选取
正样本选择defaultbox和groundtruth的iou最大的作为正样本,对于任意一个defaultbox,如果iou大于0.5,也认为是正样本
负样本,除了正样本,都可以定义为负样本,但是在训练过程中,defaultbox匹配到groundtruth的很少基本就十几个,而负样本很多的话,就会造成样本不平衡
因此对负样本的confidence loss,如果它更小,则越有可能是目标,因此取最大的几个(大约与正样本比例为3:1)
这种称作hard negatibe mining方法
# 计算损失
损失分为两个类别损失和定位损失
其中N为匹配到的正样本的个数,为1