# GPT:generative pre-training
# GPT-1
# Background
Improving language understanding by generative pre-training
- Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
- 无标注的数据有很多,标注数据很少,因此本文是通过无标注数据预训练,然后在有标注数据上微调
- 之前的方法都是学词向量,但是遇到不同任务时,还要做不同的下游模型,这里作者统一用transformer的decoder结构,只需要改变输入格式就能应对不同任务,无需再改模型结构
- 当时的困难有两个,一是不清楚用什么目标函数,虽然有LM、QA等各种任务,但是往往一种方式在另一个任务上效果就不太好了,没有一个统一好的目标函数;二是如何选择一种有效的将学习到的表征迁移到子任务上;
作者最终选择了Transformer作为基础架构,因为发现transformer在不同任务的迁移学习上更robust,原因是其结构化的记忆模块能够处理更长的文本信息
# Unsupervised pre-training
GPT使用标准的语言模型在无标注的数据上进行预训练,极大化似然函数(已知前k-1时刻的值,预测k时刻的值),可以如下表示,U为窗口内的所有词,乘一个W参数,加上一个位置权重W,然后一起通过transformer block,得到一个输出,把这个输出乘上一个参数矩阵W,最后softmax,结果就是当前时刻值的概率分布
这里跟Bert的区别是,bert是有掩码的语言模型(MLM),在预测其中某个词的时候可以看到整个句子;而GPT是标准语言模型,预测当前词的时候,只能看见之前的词,后面的词模型看不到;
(因此GPT是完全的预测未来,难度比bert高很多,bert相当于完形填空)
# Supervised fine-tune
微调的时候是有标号的,每次给一个序列,预测y;实际上作者在微调的时候发现,将目标函数设置为一起预测标号和预测下一个词,效果更好
微调的目标函数确定好之后,下一个问题就是如何将不同任务统一为这种形式:有标号的数据和对应的标号y
# Task-specific input transformations
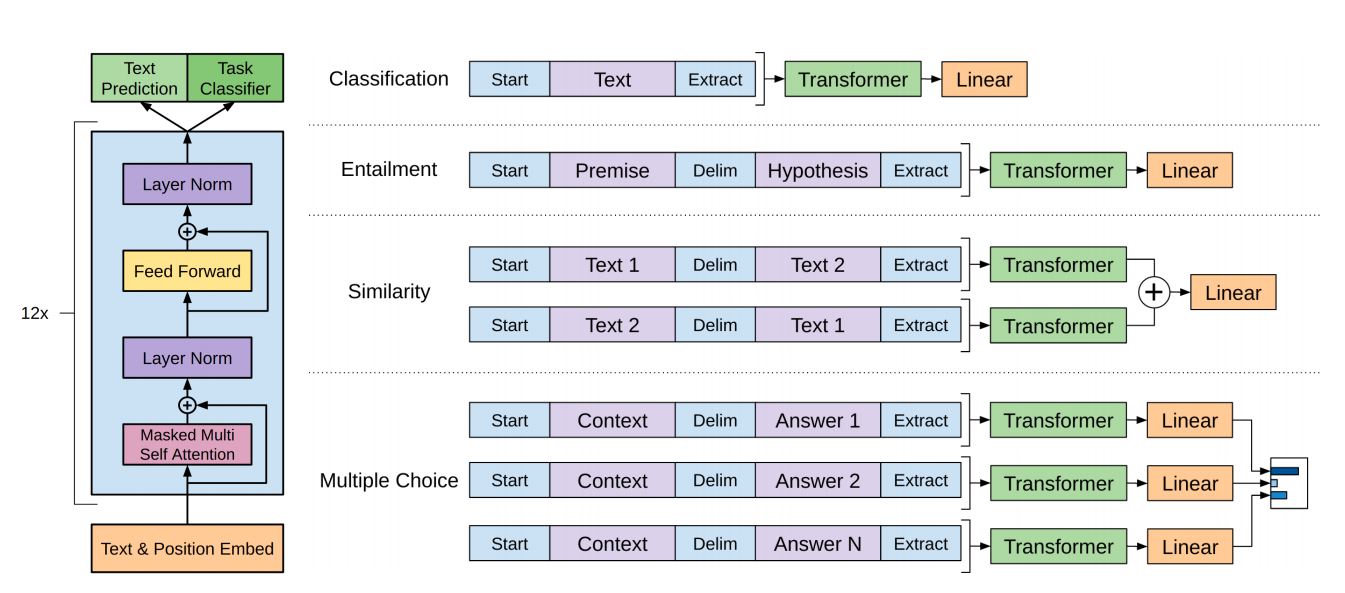
图1. 将不同任务统一为句子+label的形式
图1展示了如何将不同任务统一形式输入模型做微调,核心实际上就是把不同文本串成一个序列
# GPT-2
Language models are unsupervised multitask learners 语言模型是无监督的多任务学习器
- Liu, Pengfei, et al. "Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing." ACM Computing Surveys
55.9 (2023): 1-35.- gpt被bert打败了,因此想把模型做的更大,数据更多,构建了百万数据集WebText,模型变为15亿参数;但是仅仅加大模型和数据是不够的;
- 当时业界主流是在一个数据集上训练好,然后去对应的任务上测试,因为模型的泛化性不太好;第二是当时有多任务学习(Multi-task learning)的方法,就是在多个数据集上一起训练,然后构造多个损失函数,可以提高点泛化性,但是这种方式在nlp上效果也一般,因为同样需要很多不同标注数据,而且也要微调
- 因此作者提出了一个zero-shot的设定,就是只拼预训练,不需要下游任务的信息,直接做预测看效果,比模型的泛化能力
# 跟GPT-1的不同
因为不看下游fine-tune,没有标号数据了,因此要预测的东西和模式,必须在预训练的时候都加入,因此作者举了个例子,比如要进行翻译任务的时候,将输入设定为 (translate to french, english text, french text),这样的话,再次进行翻译的时候,先输入模型一个translate to french,模型就能知道要翻译后面的东西了;再比如阅读理解的时候,输入为(answer the question, document,
question, answer),模型看到answer the question的时候就知道要回答问题了
# Datasets
爬取了大量数据,但是数据很脏,因此取了别人点赞数高的数据作为高质量数据
# 结果
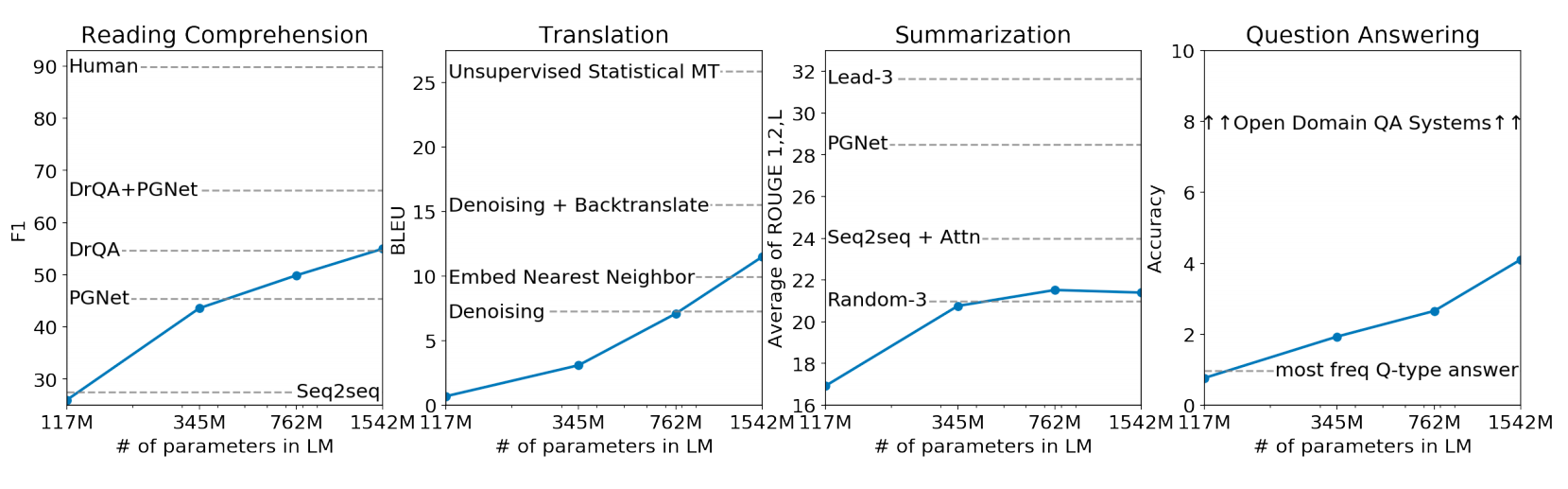
图2. GPT-2在不同任务上的表现
从结果上看,模型越大,效果越好,所以还是存在可能,把模型做的更大,理解能力更强的
# GPT-3
Language models are few-shot learners 语言模型是few-shot学习器
- Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.APA
- GPT-2没有用任何下游数据finetune,GPT-3还是类似GPT-2的理念,不比微调,而是通过预训练来看模型的效果;但是实际上像人也是看到一些例子后,理解能力会更强,因此作者考虑用少量的数据来训练,也就是few-shot learning
- 大力出奇迹,搞了1750个亿参数的模型,模型大小和数据都是GPT-2的一百倍
- 提出个概念meta-learning和in-context learning
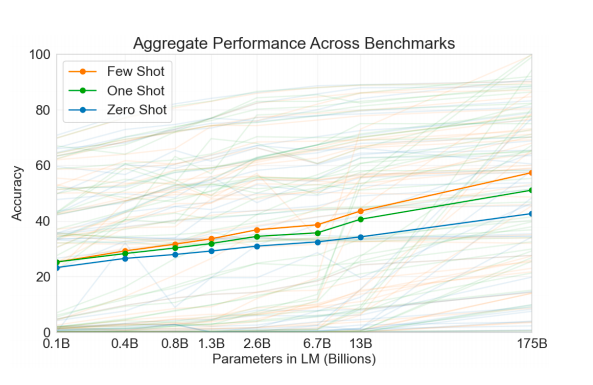
图3. 在不同任务上的效果
在zero-shot、one-shot和few-shot上的不同效果,并且随着参数增加,效果一直提高;

图4. 不同任务是怎么做的
在不同任务的时候,给了不同的任务提示,用“⇒”告诉模型可以输出了;每次不用给到的数据不参与微调模型的参数
# 架构
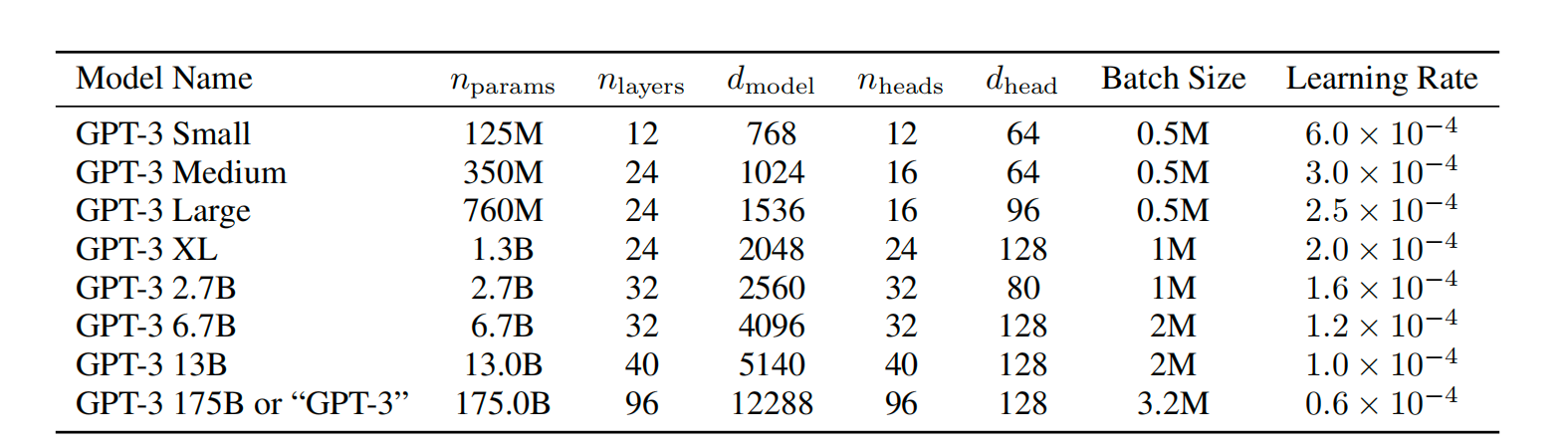
图5. 不同size的GPT
架构跟GPT-2差不多,主要是加了层,其他的是用了sparse transformer的相似结构,用了pre-normalization
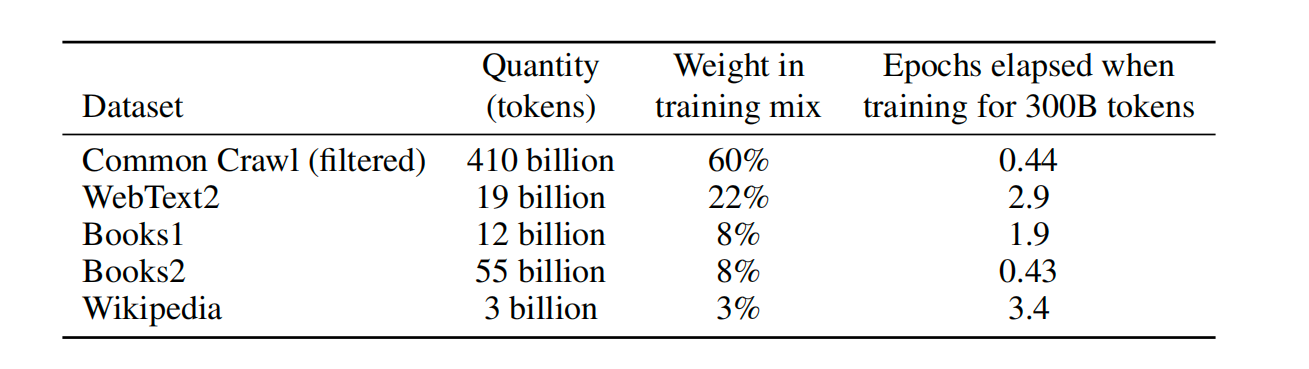
图6. GPT3的数据集
# Limitation
- 模型是真的学到了东西还是从大量数据中去检索到的
- 对生成效果不太好
- 训练太难了。。