# Transformer: Attention is all you need
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).APA
- 提出了个简单的结构,仅仅依赖注意力机制,而没有用循环(RNN)和卷积(CONV)
- RNN系列的缺点:
- 结构无法并行,下一个词需要依赖上一个词的结果,计算性能差;
- 历史信息需要一步步往后传,如果时序比较长,早期的信息可能在后面丢失,如果不想丢失,那么每一步的结果都要保存,占用很多资源
- 其他工作,比如用卷积神经网络替换RNN,**卷积神经网络对比较长的序列难以建模,**但是本文的Transformer可以一次看到所有信息;但是卷积网络可以有多个输出通道,每个通道可以识别不同模式,因此Transformer中加了MultiHead-Attention的机制
- 在本文工作之前,Attention是跟 RNN一起用的,主要用在如何把编码器的东西传给解码器;本文工作是只用Attention,因此就可以并行计算,而且效果很好
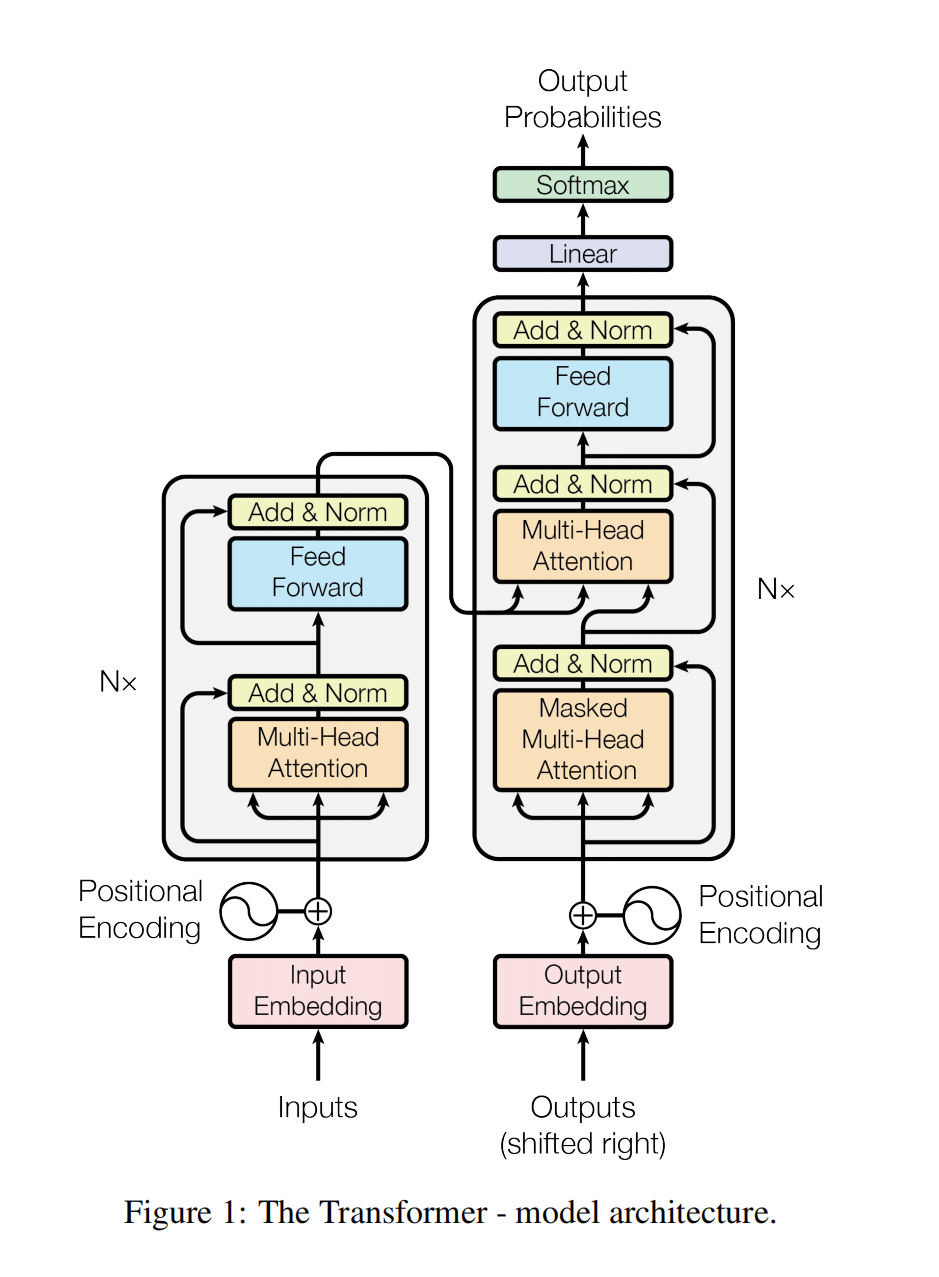
# Embedding
# Embedding
编码和解码的embedding是一样的,把权重乘了根号,因为在学embedding的时候,可能将embedding的L2long学的比较小,但后面会加上position embedding,因此把两个放到近似相同的量级上(都是-1到1之间)
# Position Embedding
Attention是没有序列的位置信息的,因此在embedding这里加进去;使用不同周期的cos函数来表征的,因此在-1和1之前抖动
(对比RNN是上个时刻的输出作为下个时刻的输入,因此本身就是时序的)
# Encoder
# 基本架构
Encoder部分包含6个Layer,每个Layer由2个sub-Layer,每个sub-Layer包含一个MultiHead-Attention和一个point-wised feed forward network,每个sub-Layer后都有先接一个残差,然后LayerNorm,因此每个sub-Layer最终为:
- Encoder = 6 * Layers
- Layer = Multihead-Attention + FFN
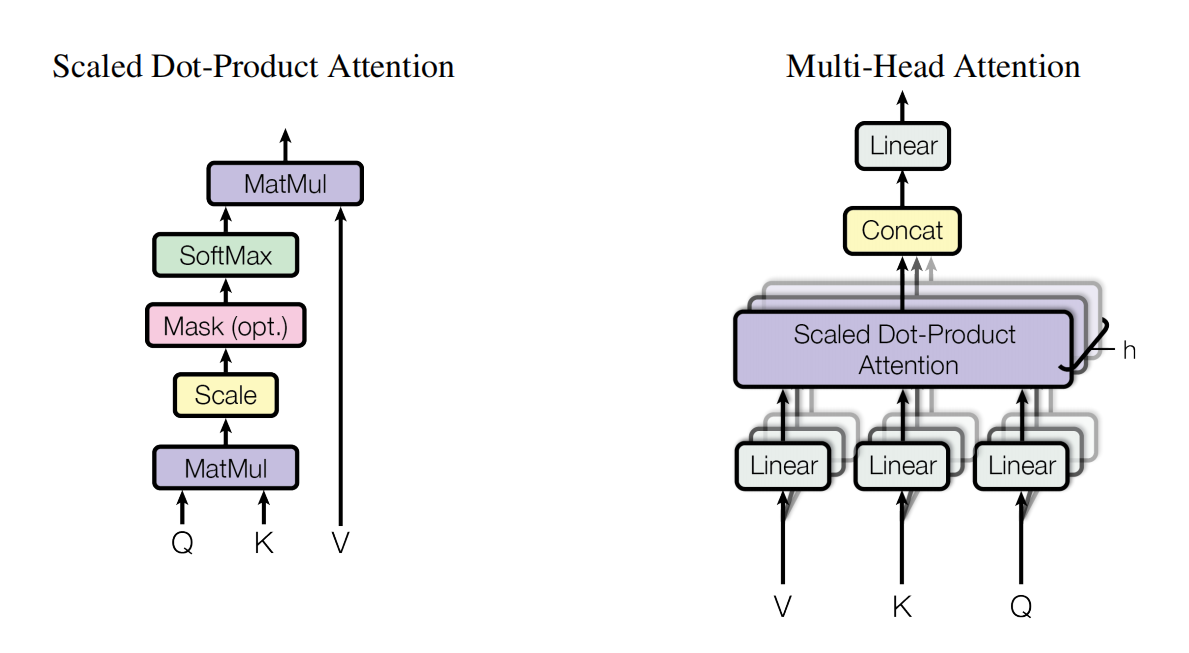
图2. scaled Dot-Product Attention 和 Multi-head-Attention
# Scaled Dot-Product Attention
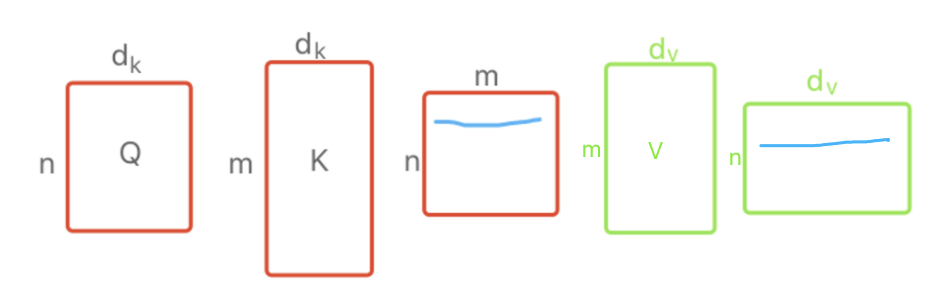
Attention是计算一个query和key的相似度来得到attention score;之前的工作有不同Attention,比如add-attention和dot-product-attention,作者这里的改进是做了一个放缩,将Q*K的结果用根号进行缩放,因此这里作者取名Scaled Dot-Product Attention,缩放的原因是因为当过大时,即向量长度更长,点积后的结果可能很大和很小,因此Softmax最大的值就更靠近1,其他值更靠近0,此时梯度比较小,会很难训练,因此缩放是个比较好的方式
# Masked Multi-head Attention
Masked Multi-head Attention中的Mask是因为在计算t时刻的attention,时,此时只能看到前k-1时刻的情况,理论上是不知道后面时刻的值的,因此将后面的值Mask掉,具体就是取一个很负的值,此时softmax出来的值对应的权重都为0,只有k-1时刻和之前时刻的值;Multi-head是对于单个head的attention,不如将其投影到多个比较低的维度上去,对于每个维度的输出,在最终并到一起,再投影会来得到最终的输出;
为什么用Multi-head Attention? 是因为dot-product本身是没什么参数可以学的,就是两个点积,但是这里的linear的权重w是可以学习的,网络内部通过不同方式去处理;也就是给你h次机会,使得在投影进去的度量空间里匹配不同模式
# Self-Attention
Self-Attention:这里就是q、k、v都是自己,QK就相当计算每个token的相似度作为score,最终加权到v上去,这里肯定是自己跟自己的score最大,但是其他词对当前词也会有影响,而且分成多个head就投影到多个空间上去,肯定可以学到不同空间的影响
# Point-wise Feed Forward Network
作者将一句话中的每个词看作一个个点(point),因此名字叫point-wise;实际上就是个MLP,单个隐藏层,把输入从512扩大到2048,然后再缩放回去,这里的max就是激活函数Relu
这里的作用就是前面Attention已经对于每个token都把这个序列信息进行了一个抽取,然后这里通过对每个token的序列信息进行进一步加工,然后再输出
这里跟RNN的区别就是Transformer是通过attention将一句话完整的序列信息整合到每个token上,而rnn是每次将上一时刻的信息传给下个时刻,然后跟当前时刻的词一起输入;因此序列信息的整合方式不同,两者都用了MLP做最终的信息整合
# Decoder
Decoder部分也是包括6个Layer,除了Encoder中相同的2个sub-Layer,在这之前,还插入了第三个sub-Layer:Masked-Multihead-Attention模块;同样每个sub-Layer后都有先接一个残差,然后LayerNorm;
- Decoder = 6 * Layers
- Layer =Masked-Multihead-Attention + Multihead-Attention + FFN
# Transformer的三种Attention
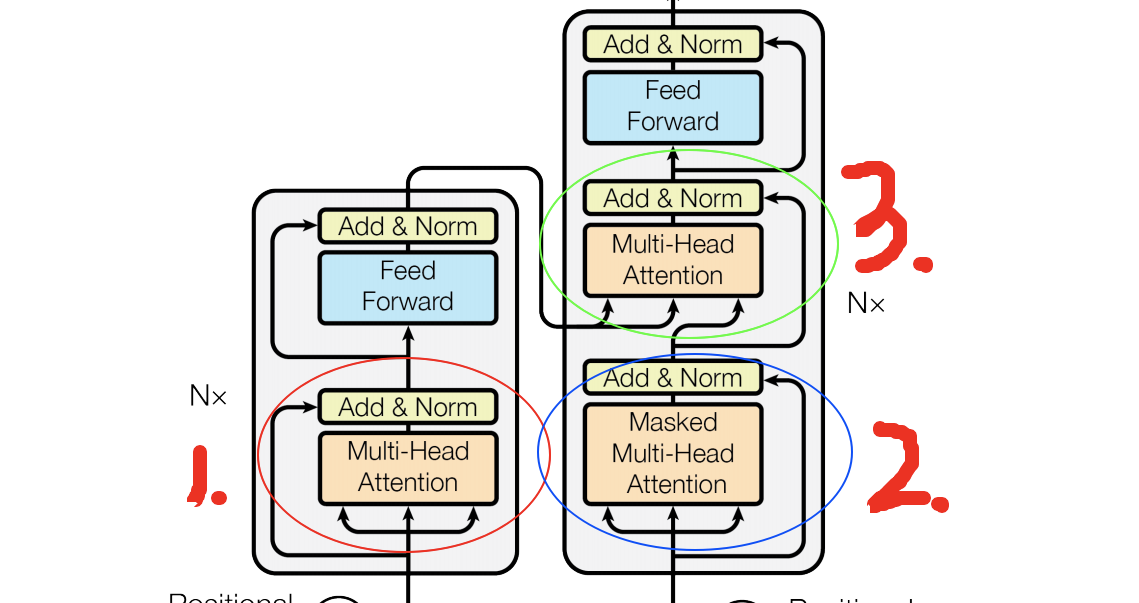
图4. Transformer中的3种Attention
整个Transformer有三种Attention
- encoder中的self-attention
- decoder中的masked self-attention
- decoder中解码时的attention
- query为mask-attention的输出,key、value为encoder的输出,相当于看query和训练到的key的相似度,得到attention score,最终作用在学习到的value上,产生最终的输出
# 关于模型
- 题目名字为“Attention is All you need”,实际上不只是Attention,少了MLP、残差、position都训不出东西来
- 原本图像用cnn,文本用rnn,这个模型统一都用attention提取特征了,某种程度上的统一
- attention的基本假设太简单了,因此对数据信息的抓取能力变差了,因此需要多层,多数据,导致现在的模型都必须很大,数据需要很多