# 决策树
# 熵的历史
有两件事发生的概率,如果同时发生,则概率为联合概率,如果是独立的,则联合概率为各自概率的乘积。
如果想定义一种新的概念,希望如果是独立的,则所形成的交互的度量视为0,也就是满足可加性,也就是把乘积变成加和。考虑到取log可以实现,并且将其视为减函数(这个值越大,不确定性越小)。
因此定义了一个东西:,称为信息量
把概率算上求期望就是熵:
# 条件熵
发生包含的熵,减去单独发生包含的熵:在发生的前提下,发生“新”带来的熵,称为条件熵。
# 决策树思想
开始的时候,有一个熵,最终划分完后,熵为0,也就是每次划分都使得熵下降一点,最终达到0。
这是一个贪心算法,每次按照熵下降最快的分法进行分类。
决策树采用的是自顶向下递归的方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子结点处的熵值为0,此时每个叶节点中的实例都属于同一类
# 决策树学习的生成算法
# ID3
Iteractive Dichotomister(迭代二叉树,第三个版本)
信息增益表示得知特征A的信息而使得类X的信息的不确定性减少的程度
特征对训练集的信息增益为,定义为集合的经验熵与特征给定条件下的经验条件熵之差,即
显然,这即为训练数据集和特征的互信息。
是不考虑任何特征时类发生的熵,是确定特征后,发生的熵,相减就是特征对发生的影响程度,就是互信息,也是信息增益。
注意:如果把编号作为一个特征,那么选编号作为分类特征时,则一次就可以分完,就会出现问题,此时这个特征(编号)的熵特别大(因为每个编号的概率都相等),我们不希望这个特征混乱,所以用信息增益除以特征的熵,作为信息增益率来作为特征选择的度量,会更好,这就是C4.5算法 。
ID3算法使用信息增益进行特征选择
- 取值多的属性,更容易使得数据更纯,其信息增益更大
- 训练得到的是一颗庞大且深度浅的树,不合理
因此尝试用其他指标进行特征选择
# 其他目标
信息增益率:信息增益/特征的熵
Gini系数:
一个属性的信息增益率/gini系数越大,就说明这个特征使得数据从不确定到确定的能力越强
# 决策树的评价
用于评价一颗决策树的好坏。比如手上有多棵树,哪棵树比较好。
对于所有叶子结点,每个节点都可以计算一个熵,纯节点的熵为0,均节点的熵为lnK,对于所有熵求和,则该值越小,则分类越精确,又因为每个节点的样本数目不同,因此可以使用样本数进行加权求和,评价函数表示为
也可以称为损失函数。
# 决策树的过拟合
# 剪枝
# 预剪枝
在生成树的时候,规定深度不能超过某个值,或者规定某个节点的样本数不能低于某个值,或者某个节点的熵不能小于某个值,对这些节点就不再继续生成。
# 后剪枝
先把树生成完,然后剪。
基本思路,由完全树T0剪枝部分节点,得到T1,再剪枝一些节点,得到T2,不断剪枝,得到根节点Tk,最终取判别这n棵树,哪个的损失函数最小。
当叶子结点越多,决策树越复杂,损失越大,因此在这棵树的损失函数里添加一个关于叶子数量的惩罚项
剪枝前为,剪枝后为$$,只有一个叶子(就是其本身),各自的损失函数可以计算得到和,让其相等,可以计算出的大小,也就是当这个值的时候,剪枝和不剪枝的效果相同。
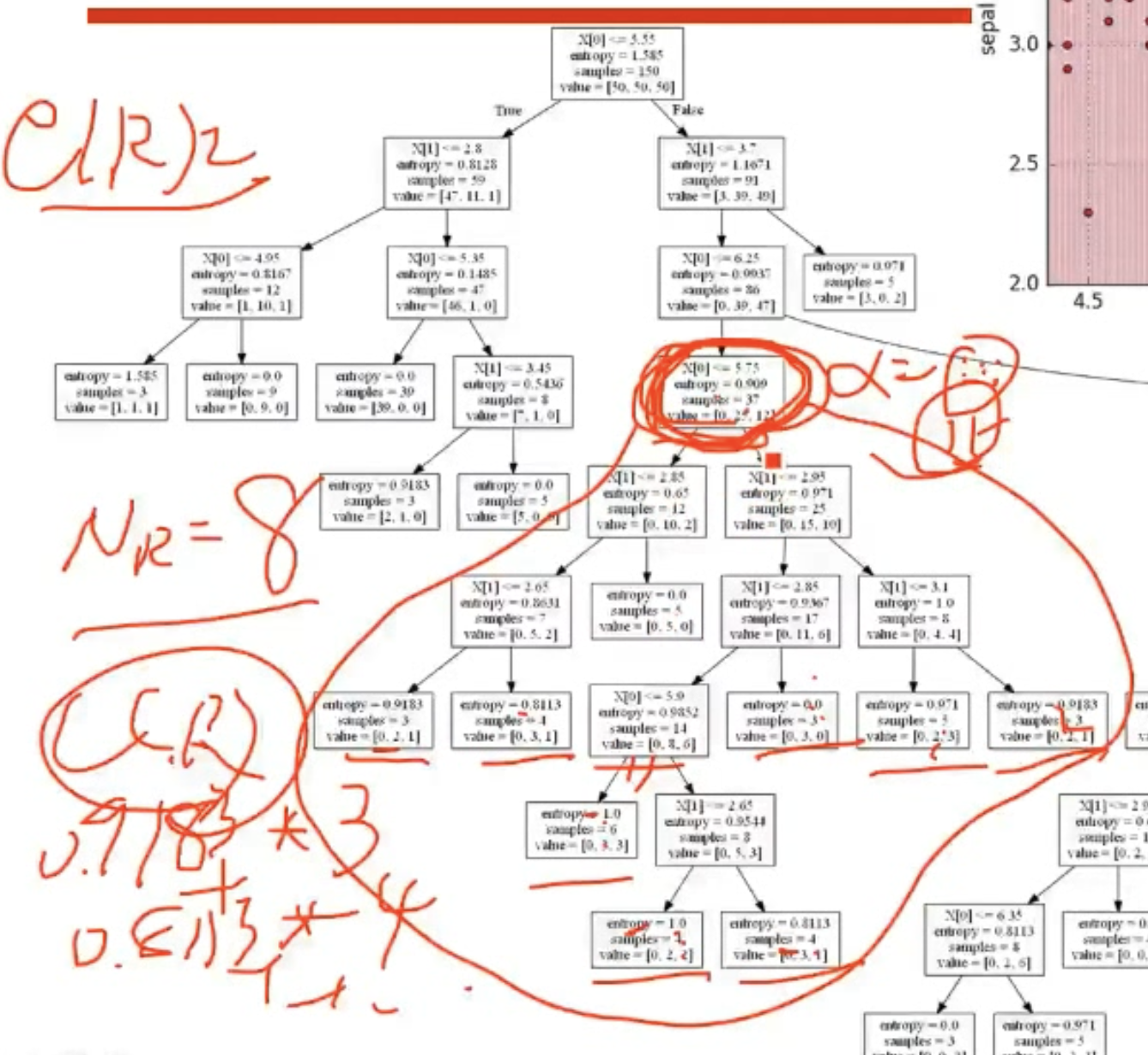
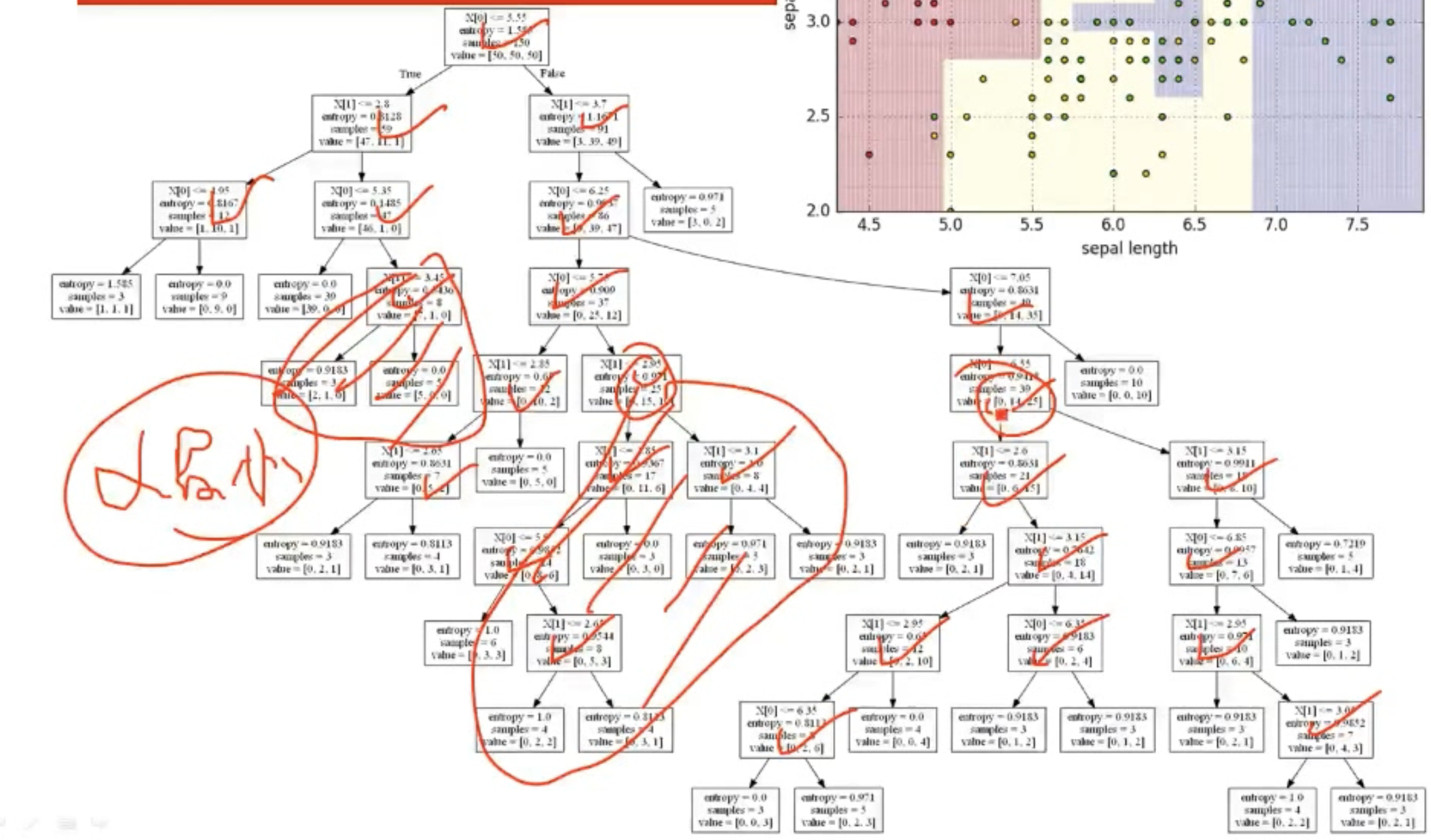
将所有内部结点的值都计算出来,选择一个最小的进行剪枝,剪完之后,再继续按照这种方式剪枝,得到若干棵树,使用测试数据检验这些树,哪些损失最小,则选择哪棵树。
# Bootstraping
自举,就是自己提高自己,比如一开始用机器语言,然后用机器语言造一个汇编编译器,然后用这个编译器加一些指令造更高级的编译器,再用这个造c的编译器,再造c++的编译器,再造java的编译器等等,这个过程就是自举的。
# Bagging
分类器中,从样本集中重采样(有重复的)选出n个样本,在所有属性上,对这n个样本建立分类器(ID3、C4.5、CART等等)。重复以上两步m次,即可以获得m个分类器,将数据放在这m个分类器上,最后根据这m个分类器的投票结果,决定数据属于哪一类。
# 随机森林
随机森林在bagging的基础上做了修改,从多个特征中随机选择几个特征生成决策树
- 从样本集中用bootstrap采样选出n个样本
- 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立cart决策树
- 重复以上两步m次,建立m棵cart决策树
- 这m棵决策树形成随机森林,通过投票表决结果
有点像dropout,防止过拟合,减小了预测方差,预测值不会因训练数据的小变化而剧烈变化
# 样本不均衡的常用处理方法
- 使用其他指标,比如AUC
- 样本多的种类欠采样
- 做随机欠采样
- A类分为若干子类,分别与B输入模型
- 基于聚类分为多个簇,然后分别与B输入模型
- 样本少的种类做过采样(重采样)
- 避免欠采样造成信息丢失
- 样本少的数据随机插值得到新样本
- 代价敏感学习
- 降低多样本的权值,提高少样本的权值