# 推荐系统介绍
# 目的
- 面对信息过载采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品
- 解决如何从大量信息中找到感兴趣的信息
- 解决如何让自己生产的信息脱颖而出,受到大众的喜爱
# 推荐系统基本思想
利用用户和物品的特征信息,给用户推荐那些用户喜欢的特征物品(知人所想)
根据用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品(物以类聚)
找到跟用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品(人以群分)
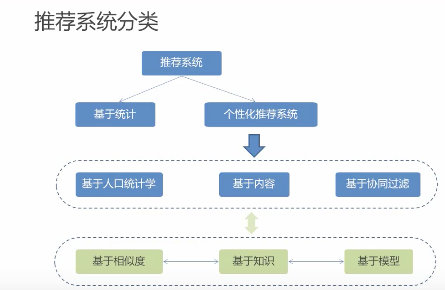
# 推荐系统的分类
- 根据实时性分类
- 离线推荐
- 实时推荐
- 根据推荐是否个性化分类
- 基于统计的推荐:热门、热搜
- 个性化推荐
- 根据推荐原则分类
- 基于相似度的推荐:物以类聚、人以群分
- 基于知识的推荐:基于规则
- 基于模型的推荐:基于机器学习
- 根据数据源的分类
- 基于人口统计学的推荐:用户画像等
- 基于内容的推荐
- 基于协同过滤的推荐:基于行为数据
# 推荐算法简介
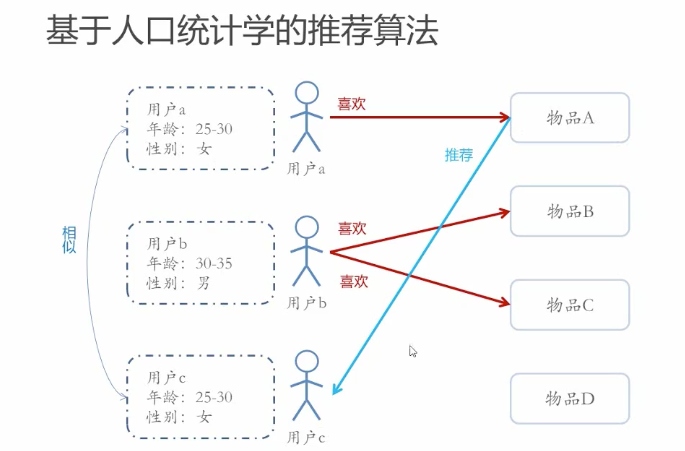
# 基于人口统计学的推荐
已知用户信息,进行人以群分的推荐
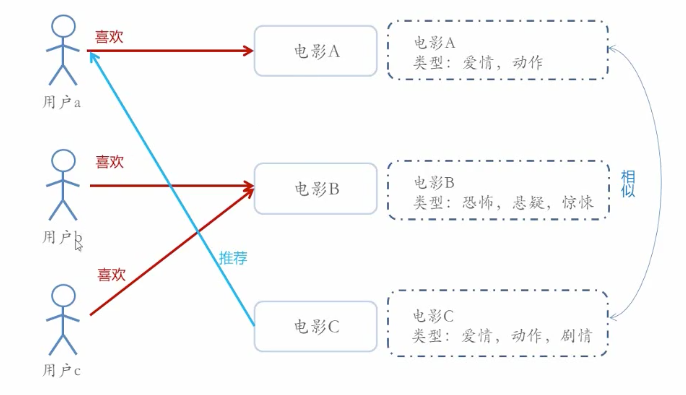
# 基于内容的推荐
已知物品的信息,进行物以类聚的推荐
# 基于协同过滤的推荐
协同过滤(Collaborative Filtering,CF),同时跟物品和用户有关联,利用物品和用户的协同进行进行筛选推荐,过滤出推荐信息,称为协同过滤。
- 基于近邻的协同过滤
- 基于用户(User-CF)
- 基于物品(Item-CF)
- 基于模型的协同过滤
- 奇异值分解
- 潜在语义分析
- 支持向量机
基于内容的推荐方法,主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过的物品内容(CF用到所有用户和所有物品的协同信息)
CF比较依赖历史数据(那个用户和物品的协同矩阵,一般是稀疏的,因为只要少量的人去评价,少量的物品被评价),所以冷启动的时候比较困难,因为没有任何数据,此时可以直接给个热门推荐,或者根据用户的标签进行推荐,所以真正使用时,是多种推荐方式进行结合的。
# 混合推荐
- 加权混合:将不同的推荐按照一定的权重组合起来,具体权重的值需要在测试数据上反复试验,从而达到最好的推荐效果
- 切换混合:切换的混合方式,就是允许在不同的情况(数据量、系统运行状况、用户和数目等)下,选择最为合适的推荐机制计算推荐
- 分区混合:采用多种推荐机制,将不同的推荐结果分不同的区显示用户
- 分层混合:采用多种推荐机制,并将一个推荐机制的结果作为另一个的输入,从而综合各个推荐机制的优缺点,得到更准确的推荐
# 推荐系统的评价指标
# 离线实验
- 通过体制系统获得用户的行为数据,并按照一定格式生成一个标准数据集
- 将数据集按照一定的规则分成测试集和训练集
- 在你训练集上训练用户兴趣模型,在测试集上进行预测
- 通过实现定义的离线指标评测算法在测试集上的预测结果
优点:只要有日志,进行采集和清洗后就可以离线实验了
缺点:无法取得用户的点击率,购买转换率等等
# 用户调查
用户调查需要有一些真实用户,让他们在需要测试的推荐系统上完成一些任务,我们需要记录他们的行为,并让他们回答一些问题,进行分析
优点:数据真实,直接获取第一手资料
缺点:找到靠谱的用户比较难
# 在线实验
AB测试:将用户分成两部分,推荐系统分为两套,在线去看不同用户的行为数据,统计不同评测指标,来考察两组推荐系统的优劣。缺点就是,即使用户量很大,也需要长期的时间去收集用户的行为结果
# 推荐系统的评测指标
预测准确度、用户满意度、信任度、实时性、健壮性、覆盖率、多样性、惊喜度、商业目标
准确度评测:1. 比如很多网站都让用户给物品打分,如果知道用户对物品的历史评分,就可以从中学习一个兴趣模型,从而预测用户对新物品的评分 2. 评分预测的准确度一般用均方根误差(RMSE)或者平均绝对误差计算 (MAE)
Top-N推荐:一般是给用户一个个性化推荐列表,这种推荐叫做Top-N推荐,Top-N推荐的预测准确率一般用精确度和召回率来度量