# CLIP: Learning Transferable Visual Models From Natural Language Supervision
利用自然语言的监督信息训练一个迁移性好的视觉模型
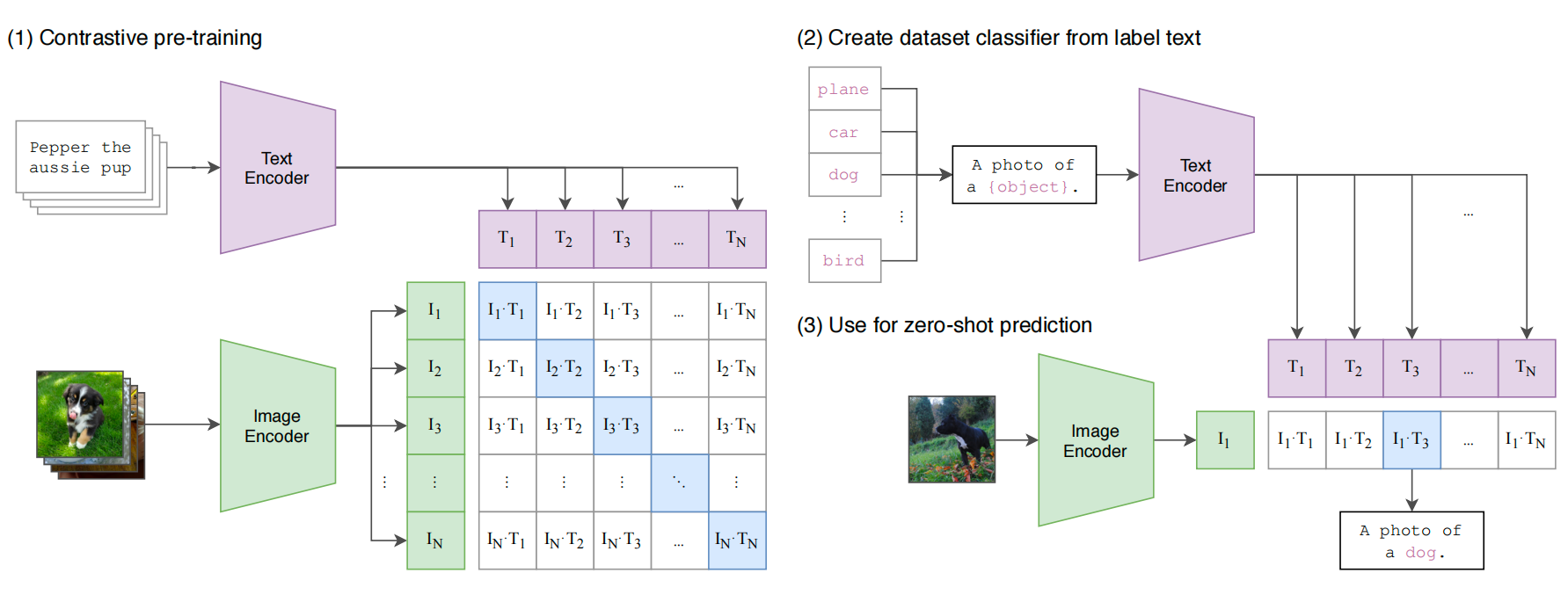
图1. clip架构
Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748-8763.MLA
- 之前工作主要是用一个特征提取器提取特征,然后用标注数据做下游任务fintune;CLIP训练最终只能得到特征embedding,进行分类问题时,作者使用prompt template构建问题模板,作者还分析了如何构建这个template去提高效果,最终比较图片特征和文本特征哪个最相似,就是哪个类别。相比于传统100个head的100分类,这里的输出可以不局限于这100类,而是可以任意定义,因为本质这里是计算相似,这里彻底摆脱了category label的限制
- 使用图片文本对进行对比学习,图文匹配对即为一个正样本,其他为负样本,因此有个正样本,个负样本
- 作者采用prompt template的方式,用一个句子而不是直接给一个单词做分类,因为单个词有时候会出现歧义,此时只提供一个单词,模型不知道让它预测什么,如果给出清晰的上下文,预测会更准确;在预训练的时候,图像-文本对中的文本往往是一个句子,而不是单个词,如果预测的时候只给一个词,可能出现distribution gap分布不一致
- Prompt engineer在template中加入更多信息,比如“这是一张「猫」的图片,一种宠物”就比“这是一张「猫」的图片”更具体,模型会将返回从全集缩小至“宠物”,会更准确;
- Prompt ensembling,作者预测是使用了多个不同prompt,综合所有的结果,也更准确,因为模型得到了多个角度的描述
- 作者对比了不同的预训练方式,比如给一张图片,预测对这张图片的描述性文本,但是对一张图片有很多种描述方式,文本生成的时候是一个字一个字产生的,因此这种训练效率就太低了,所以作者用对比学习的方式,只是预测文本和图片是否配对

图2. 伪代码
# Limitation
- clip在很多数据数据集上效果ok,但是大多数数据上,跟当时的SOTA比如MAE、ViT差很多
- clip无法处理一些更抽象或者更难的任务,**比如一些很主观的概念(异常、负向、安全)**或者一些很精细的任务,比如图片中物体计数;
- clip虽然一般讲泛化很好,但是做推理的时候如果推理数据out of distribution,那泛化能力照样很差,比如mnist…
- clip可以做zeroshot分类,但还是在给定的类别中进行选择,一种更灵活的方式——直接生成图像的标题,是完全自动的,会更好
- clip对数据的利用不太高效,仍然需要大量数据投喂
- 在整个测试集上不停做测试,做了很多超参变体,调惨工作,因此其实已经有偏见了,不是真正的zeroshot
- 数据都是网上爬的,因此没经过清洗,导致学到的clip模型会有社会偏见
- 很多任务和概念是用语言无法描述的,导致在某些情况下,clip的zeroshot比oneshot、twoshot效果更好。。