# ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
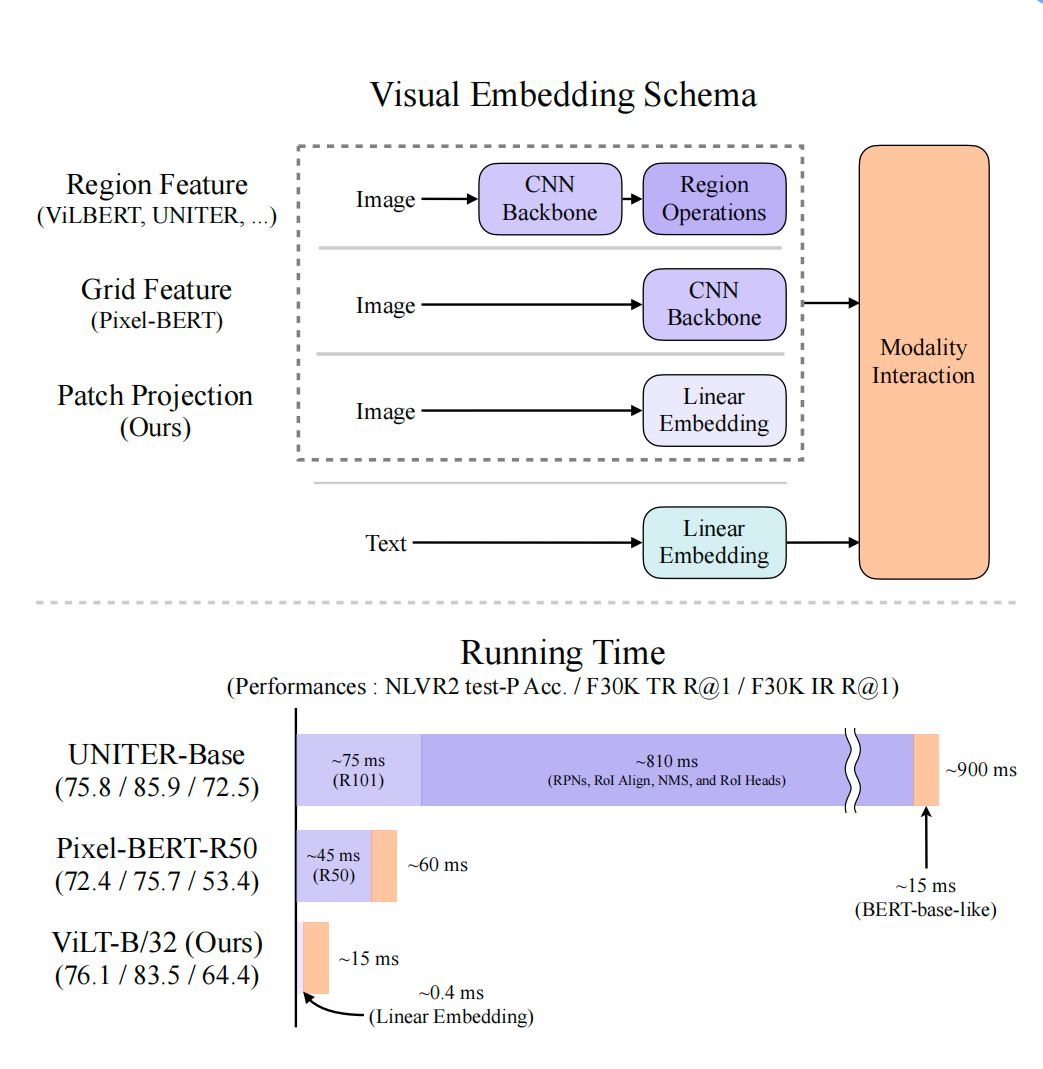
图1. 多模态经典架构
- Kim W, Son B, Kim I. Vilt: Vision-and-language transformer without convolution or region supervision[C]//International Conference on Machine Learning. PMLR, 2021: 5583-5594.
- 之前的多模态工作,文本侧是将文本直接过一个encoder得到对应的embedding,图片侧是过一个backbone,然后在通过ROI抽到一些区域性的特征,相当于是目标检测的任务,由于抽出来的特征都是区域性的,因此跟文本一样,是一块一块的,可以看作一个序列,最终跟文本embedding一起扔给transformer做模态融合;但是它的缺点如图1. 下,运行时间大部分都花在图像上;
- 本文的核心优势就是在图像上的运行时间减少了很多,实际上性能提升并不大;作者没用卷积特征和区域特征
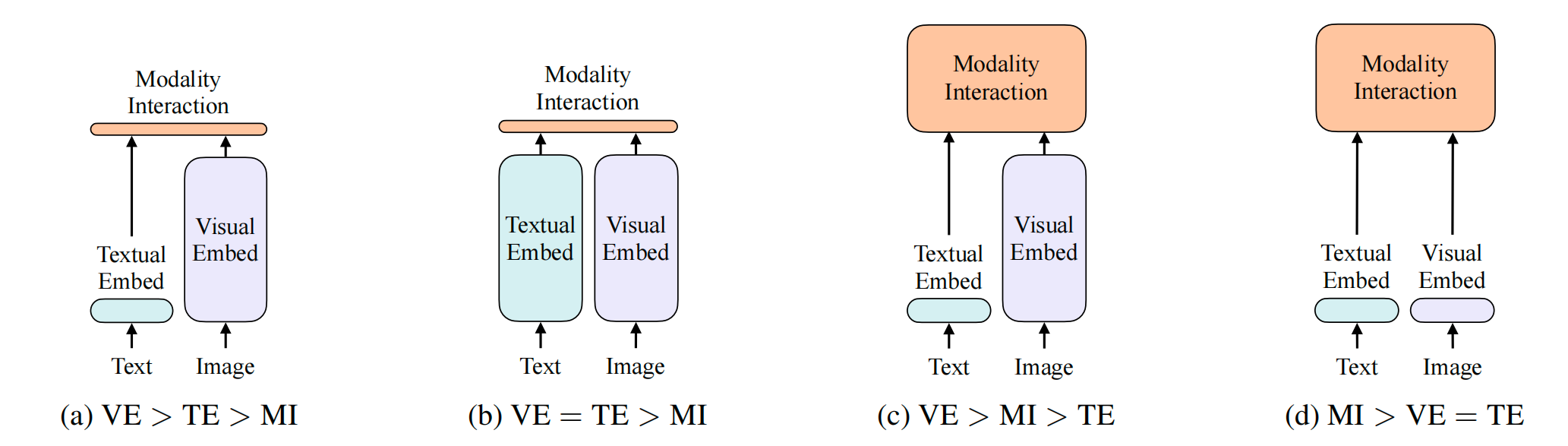
图2. 之前主要工作的模型结构,之前都是前三种,作者的工作是第四种
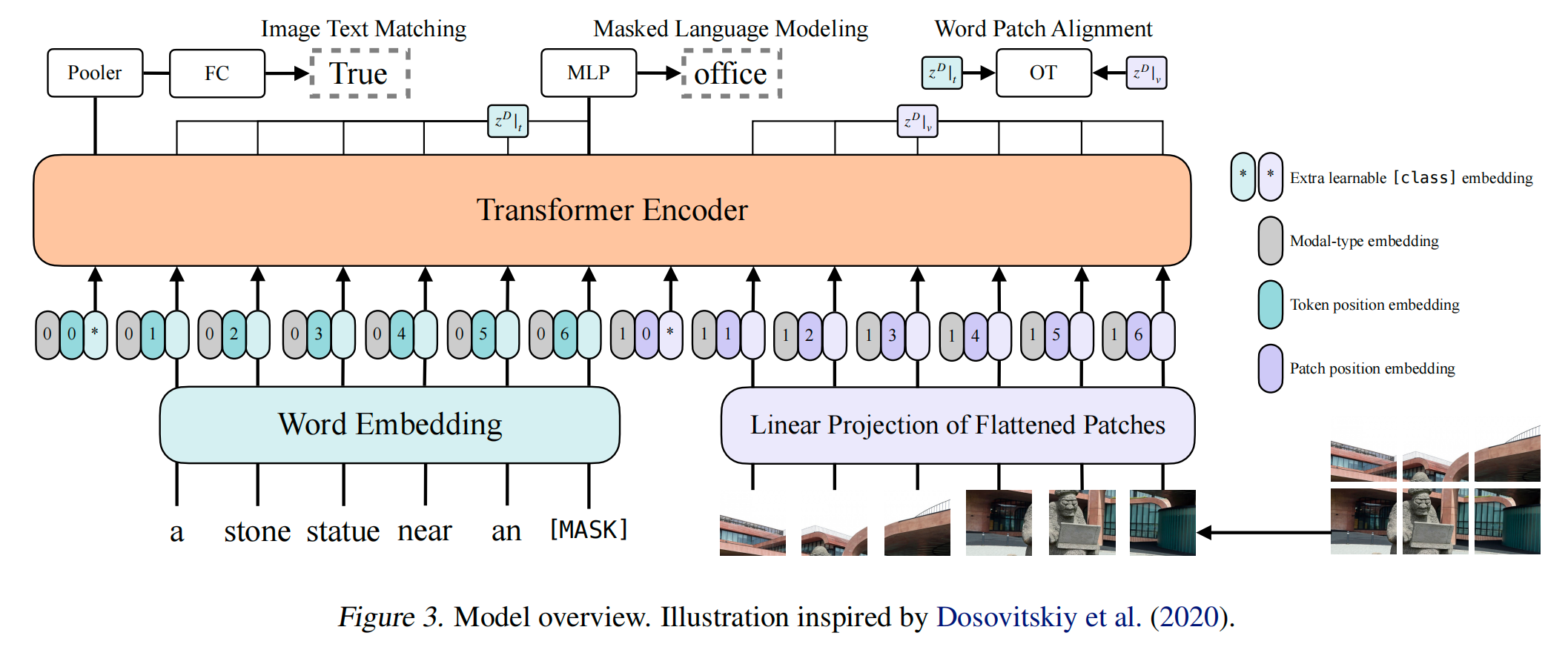
图3. ViLT模型架构(图片也过一个linear projection,而不是复杂的backbone)