# Deberta: Decoding-enhanced bert with disentangled attention
- He P, Liu X, Gao J, et al. Deberta: Decoding-enhanced bert with disentangled attention[J]. arXiv preprint arXiv:2006.03654, 2020.MLA
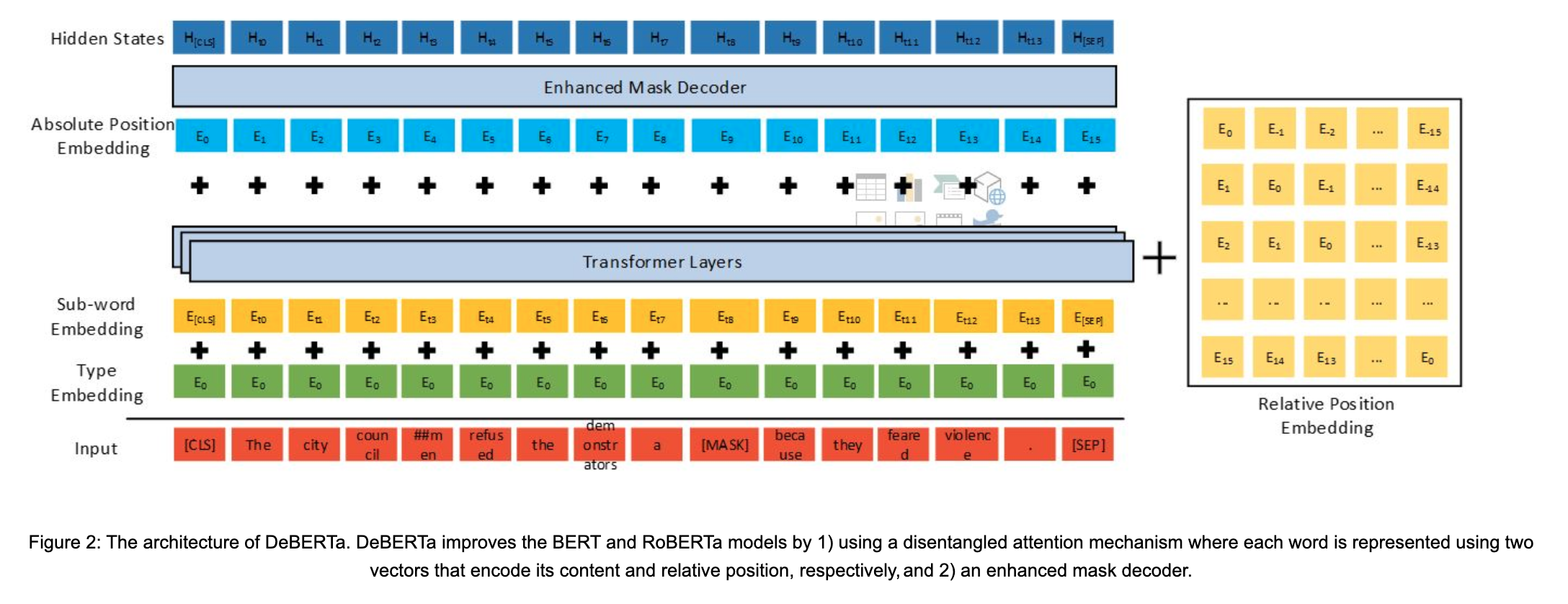
- 提出了一种全新的bert架构,deberta,使用了两种技术超越bert和roberta
- 第一是分散注意力attention机制,每个词使用两个向量分别代表内容和相对位置,并且词之间的attention score在内容和相对位置上分别计算;因为观察词对的attention权重不仅依赖于内容还依赖于相对位置;因此在计算attention的时候,计算了content-content、content-position、position-content三部分,本来第四部分position-position没什么用,就不要了
- 第二是使用一个enhanced mask decoder,将绝对位置编码在解码层进行合并,从而在与预练中预测mask word;因为虽然encoder部分使用了相对位置信息,但语言模型中句子的绝对位置也很重要,有时绝对位置包含了主语宾语等信息,因此在softmax前将绝对位置编码合并;在softmax层基于内容和位置进行掩码;
- 此外,采用了尺度不变finetune的虚拟对抗训练的方法去微调,从而提高泛化性;具体是之前的对抗训练在embedding上加扰动,但是经过很多层后,扰动可能被放大很多,影响学习,因此作者在微调前,对embedding进行标准化,然后在这个embedding上加扰动,可以限定此时句向量的方差不会太大
- 提出了一种全新的bert架构,deberta,使用了两种技术超越bert和roberta

图2. EMD结构