# Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
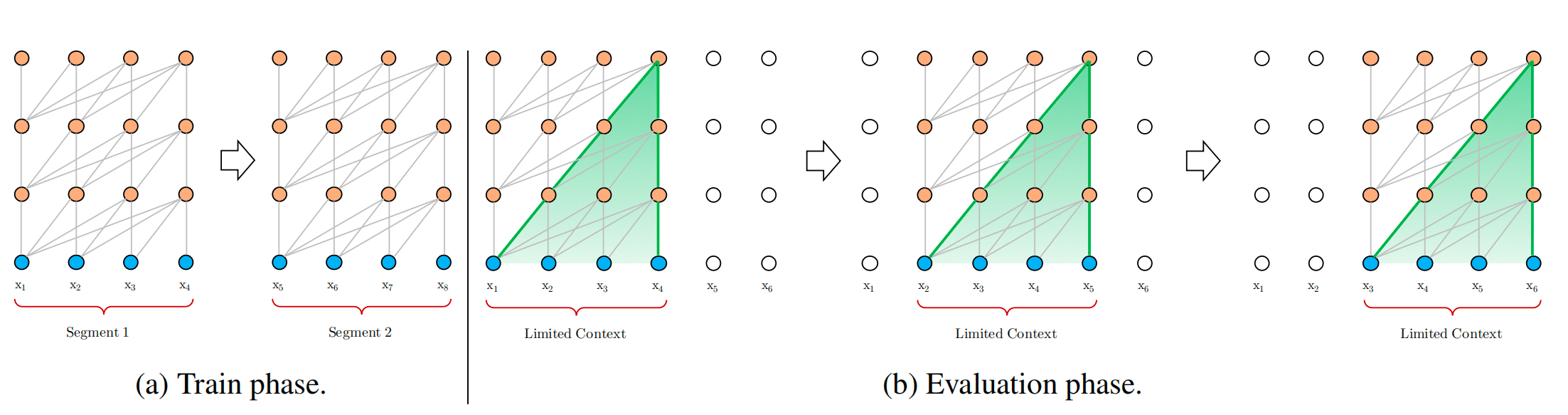
图1. 传统的固定长度
- Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
- transformer的一个出发点是解决长文本的依赖问题,但是一个很大的制约因素是文本长度;之前LSTM大概可以处理200个词左右,因此这块的提升空间很大
- 作者提出了两种方法实现长文本的依赖
- 使用片段递归机制,将一个长文本切分,之前每个片段的隐状态都保存,当计算某个时刻的片段时,同时引入上一个时刻的隐信息
- 使用相对位置编码
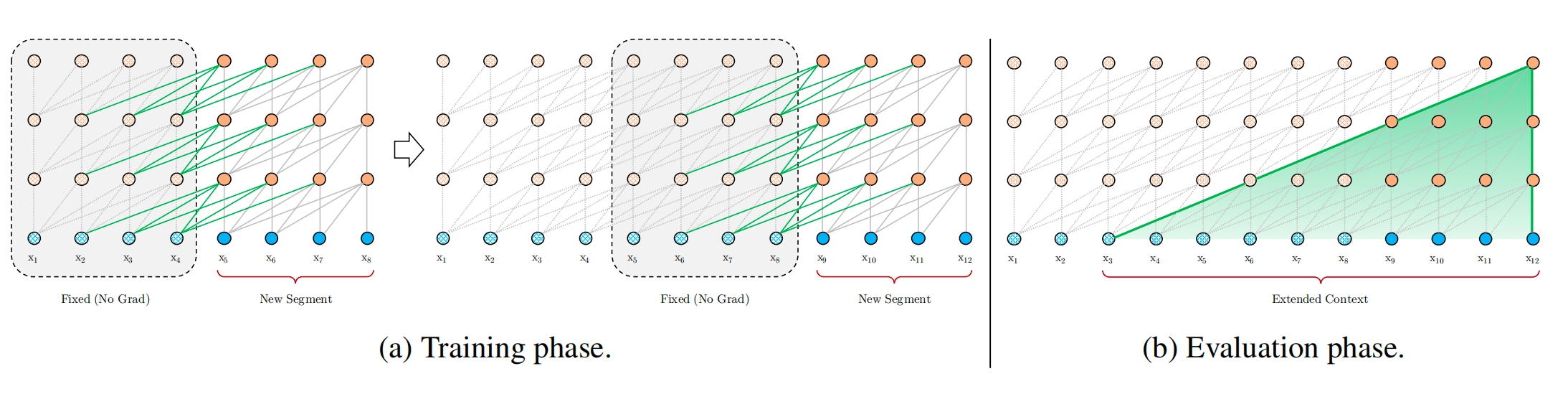
图2. 使用片段递归机制的transformer
# 具体做法
借鉴苏神的博客:https://kexue.fm/archives/8130
XLNET相对位置编码的优秀解释:http://fancyerii.github.io/2019/07/20/xlnet-codes3/#transformer_xl构造函数
# 传统相对位置编码
对于transformer中常规attention:
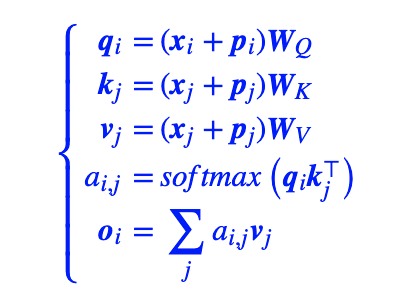
计算attention score时,对内部进行展开
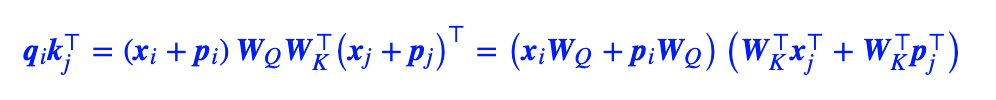



# Transformer- XL中的相对位置编码

实际上是输入一个query,当计算与key的相似性的时候,将p的位置向量替换为相对位置向量,对于query的位置向量,替换为两个可以训练的向量u、v;最终加权到v上时,直接把value的位置向量也去掉
import torch
qlen = 128 # query的长度,当前segment
context_len = 96 # 上下文context长度,根据内存大小自定义
klen=224 # key的长度,上个segment+当前segment
d_model=1024 # 相对位置编码维度
clamp_len=-1 # 将相对位置限制在某个区间
attn_type ='bi' # 双向的
bi_data = True # 双向的
"""创建相对位置编码"""
# 1. [0,2,...,1022] 长度为d_model/2=512
freq_seq = torch.range(0, d_model-1, 2.0)
# 2. inv_freq的大小还是512
inv_freq = 1 / (10000 ** (freq_seq / d_model))
inv_freq.shape
beg, end = klen, -qlen
beg, end
# 3. 前向和后向位置
# [224, -127]
fwd_pos_seq = torch.range(beg, end+1, -1.0)
# [-224, 127]
bwd_pos_seq = torch.range(-beg, -end-1, 1.0)
# 4. 定义sinusoid函数
sinusoid_inp = torch.einsum('i,d->id', fwd_pos_seq, inv_freq)
# 5. 前向和后向分别编码,然后合并
pos_emb = torch.concat([sinusoid_inp.sin(), sinusoid_inp.cos()], -1)
# 6. 扩展中间维度为batchsize,每个句子都相同
pos_emb = pos_emb[:, None, :]