# MultiModal(1)
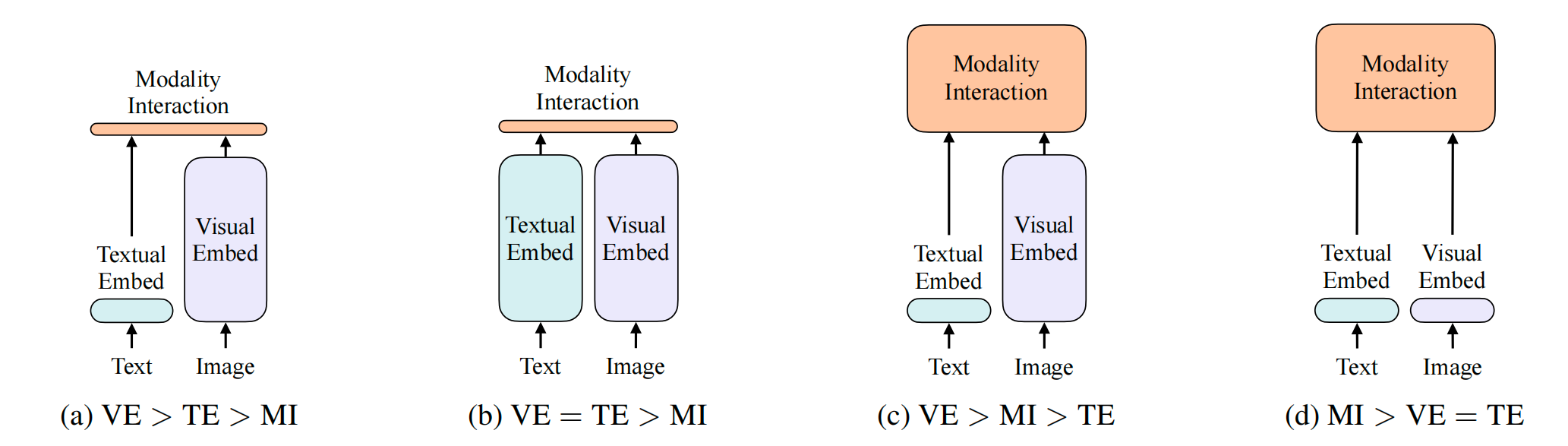
图1. 不同多模态架构
- 早期的a架构主要在文本侧直接抽一个文本特征,但是在视觉端,会用复杂的image encoder进行编码,因此计算量特别大;最终做一个简单的模态之间的交互
- 架构c在a的基础上发现,对于多模态任务,多个模态在最后的交互式非常重要的,因此将最初的模态之间的点乘改为一个transformer encoder或者更复杂的结构;但是缺点也很明显,对于image部分用了很重的目标检测器,而且再加上更大的模态融合部分,因此训练和部署都很困难,loss是word patch alignment:image-text matching loss,(ITM)
- 因此在架构d中,作者发现在vision transformer里,基于patch的视觉特征跟基于bbox的特征区别不大,也能直接拿来做下游任务,因此就可以把原来很重的image encoder目标检测器换成一层patch embedding就可以抽取视觉特征;但是文本和图片都简单的token embedding是不够的,因此模态融合这部分就很关键,ViLT将架构c的融合部分借鉴过来,用了一个transformer encoder,但是还是有很多缺点;因此后续又有ALBEF问世
- 架构b是经典的CLIP架构,是双塔架构,有两个modal,一个是text一个是image的,让同一组的文本和图片的距离拉的更近,不同组的数据距离更远,从而学到text-image特征,最终只需要一个点乘就可以得到不错的效果,尤其是图像文本匹配或检索,效果很好,可以摆脱non- vocabulary的问题,但是对QA、CLS、VR、VE效果不是特别好,因为简单的点乘还是不能分析一些复杂的情况,loss是Image-text alignment,(ITC)
- 因此多模态的主要loss有ITC、ITM、MLM
# ALBEF
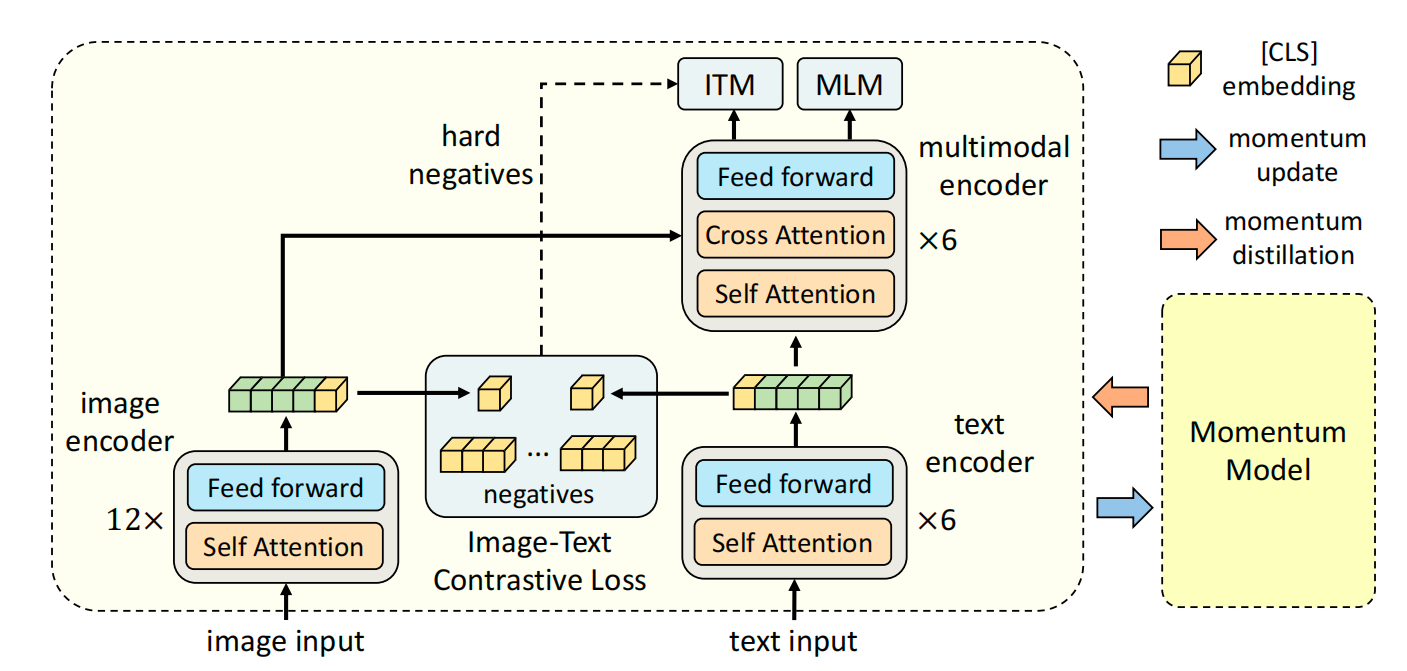
图2. ALBEF架构
Li J, Selvaraju R, Gotmare A, et al. Align before fuse: Vision and language representation learning with momentum distillation[J]. Advances in neural information processing systems, 2021, 34: 9694-9705.
- 属于c架构,图像侧用12层的transformer提取embeddin,文本侧用6层transformer提取特征,用6层transformer进行模态融合
- loss用了ITC、ITM、MLM;这些手段本质上都是常识对数据的不同视角进行分析和对齐,相当于一种数据增强,因此最终只要是语义相同的文本图像就可以作为一对;多模态中为了算多个loss,往往需要多次forward,因此训练时间很长
- 本文创新点1: 之前的工作是文本和图像分别过一个encoder,因此两者之间是没有对齐的,只是在最后融合部分进行交互,但是可能最后的融合部分很难学这种对齐的信息,因此作者加入了CLIP中的contrast loss,在fusion前进行alignment
- 本文创新点2: 实际上网上爬取的图片-文本对有时候不是完全匹配,其中有很多噪声noisy data,因此作者采用了momentum encoder的方式生成pseudo target
- 在多模态任务上,效果很好,训练推理都很快
- Momentum distillation:主要是为了解决noisy data的问题,本质上这种noisy data会因为one-hot label带来很多噪声,一种想法是不用one-hot而是multi-hot,甚至是模型另外一个输出作为监督信号;最近比较火的self-training就是专门解决这类问题,作者采用了类似的方式,使用momentum model(在已有模型上做Exponential moving average EMA),生成pseudo target,也就是一个softmax score,而不是one-hot label,在跟GT计算loss的时候,同时跟EMA产生的pseudo target计算loss,达到比较好的折中;因此实际上ALBEF有5个loss,ITC、ITC-mom、MLM、MLM-mom、ITM

图3. EMA的方式,产生伪标签
# VLMo
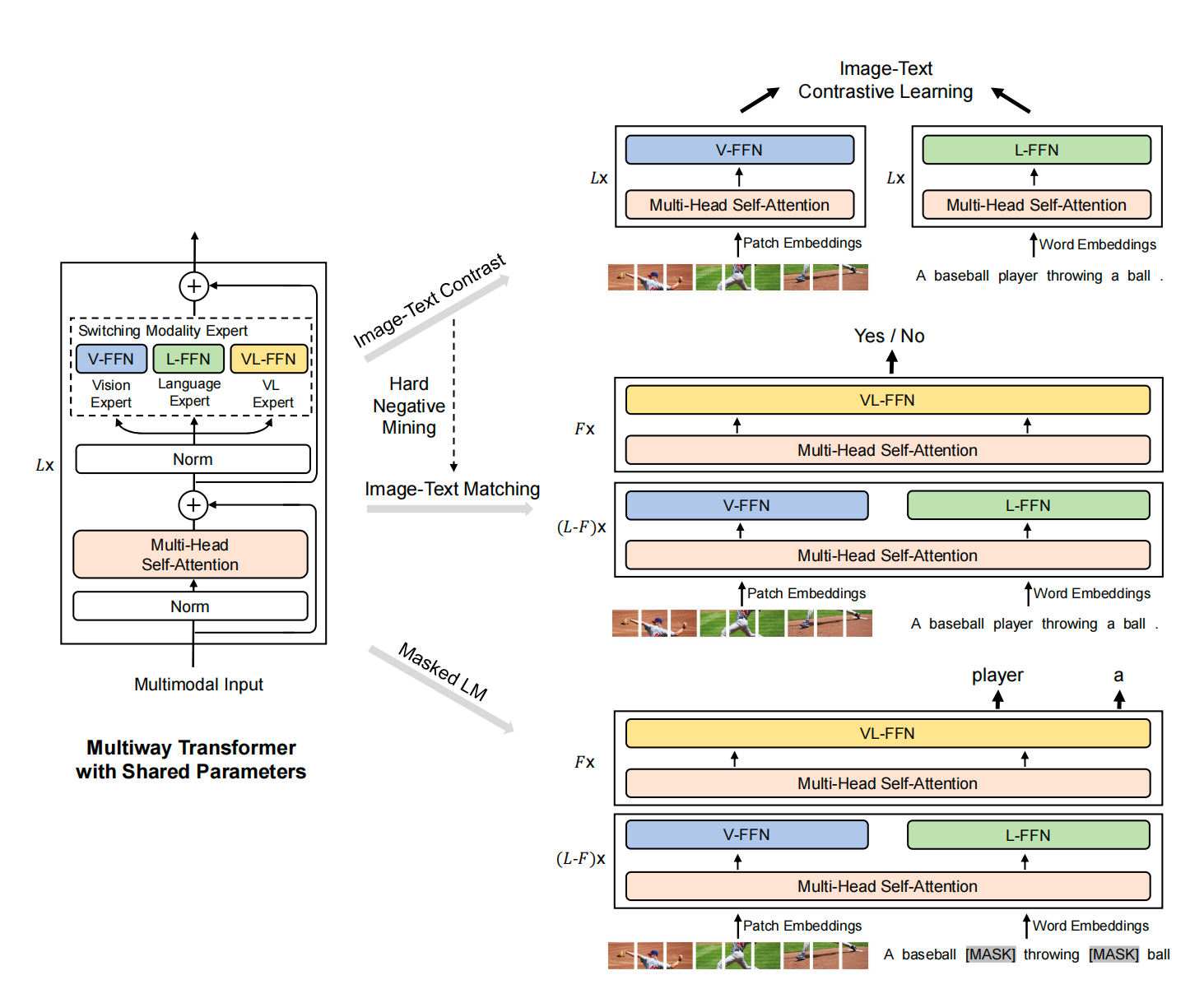
图4. VLMo架构
Bao H, Wang W, Dong L, et al. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts[J]. Advances in Neural Information Processing Systems, 2022, 35: 32897-32912.
- 主流多模态有两种架构,一种是CLIP双塔架构,image和text分别过一个encoder,最终计算下相似度,优点是对retrieval任务效果很好,可以提前算出embedding,只需计算cos就行了,但是对一些QA、AR等下游任务效果一般;另一种是单塔架构,先简单提取下特征,然后用一个复杂的层进行多模态融合,这种在下游任务效果好很多,缺点是检索任务不太好;因此作者考虑将两个方式结合起来,提出了Mixture-of-Modality-Experts结构
- 训练loss也是ITC、ITM和MLM
- 多模态领域没有单独文本或者图片那么大的数据集,因此作者提出了stagewise pre-training strategy,每次单个模态去训练,分别讲text expert和image expert上训练好,再训练多模态数据
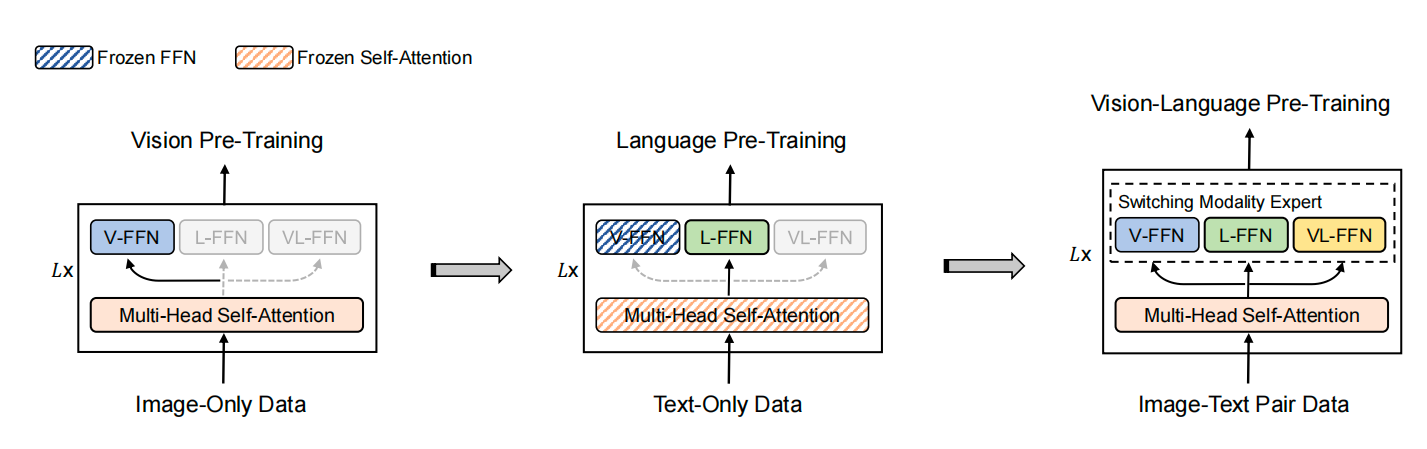
图5. stagewise pre-train路径