# Instruct GPT:Training language models to follow instructions with human feedback
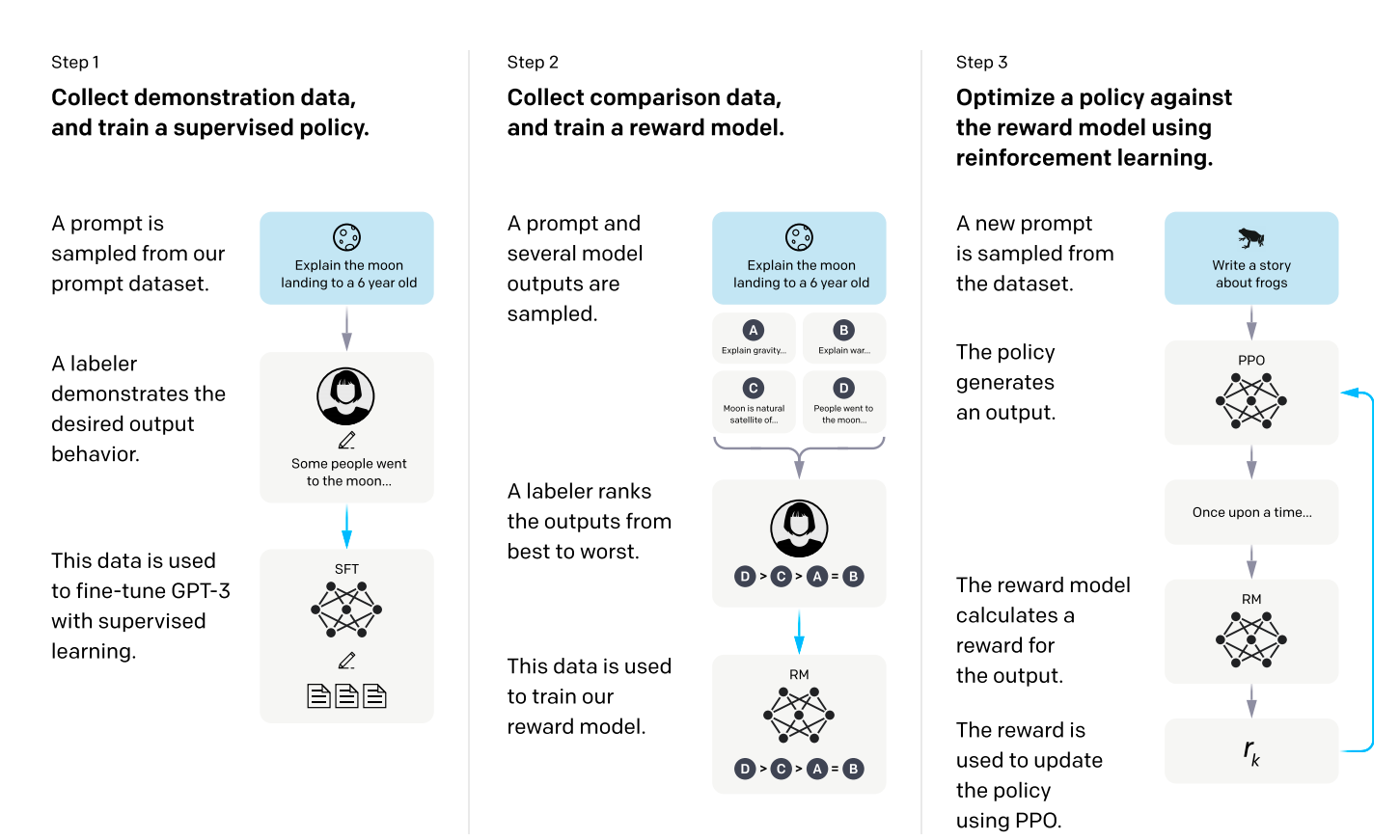
图1. RLHF
- Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
- 一般都是喂很多数据,大力出奇迹,但是对模型的控制力很差,比如想让模型学习某种知识,但是模型死活不会,其次是安全性问题,模型什么都说;因此本文的主要思想就是:再标一点数据去微调模型;
- 具体做法是首先标了一些问题,然后人工标出问题的答案;之后通过模型输出很多种答案,然后对不同的答案进行排序,做了一个排序的数据集,用强化学习去微调模型
- 主要步骤如下
- step1就是给一个问题,让人标注答案,去微调模型,就是有监督的微调;
- step2是对每个问题,模型生成不同答案,然后由人对这些答案的好坏进行排序;再训练一个reward model,输入是问题+答案,输出是分数,目的是使得输出分数的排序 跟人排序一致;
- step3就是再去用step1产生的微调模型做一个强化学习的排序模型微调模型,使得输出的答案给到reward model,得到更高的答案,做反馈,优化模型;

图2. 整体架构