# MoCo:Momentum contrast for unsupervised visual representation learning
用动量对比做无监督视觉表征学习
- He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.APA
- 对比学习通过设定一些代理任务,比如instant discrimination,判别某些样本属于同一个类别;比如NLP中的SimCSE;当时对比学习的工作主要就是这种方式,比如instant discrimination就相当于构建了一个“字典”,里面有根据正样本生成的「anchor」和「positive」,其他所有图片都是负样本「negative」;MoCo这篇论文中{anchor}和{positive,negative}样本,使用的是不同的encoder提取特征;
- MoCo对这种方式进行了抽象,将对比学习抽象成一个字典查询的任务,因此不用anchor、正负样本这些词汇,而是使用query、key这种词语;使用队列构建了一个动态字典和一个移动平均的编码器
- 作者认为NLP中无监督学习效果好的原因,是因为NLP中每个Token已经天然是一个标签了,是在一个离散的空间里,相当于已经构建了一个字典,比如MLM,可以看作是对token进行有标签的学习,比较容易建模;但是cv每张图片是连续的高维空间里,语义浓缩的不像NLP那么简洁,因此不适合建立这样的一个字典,很难去进行建模
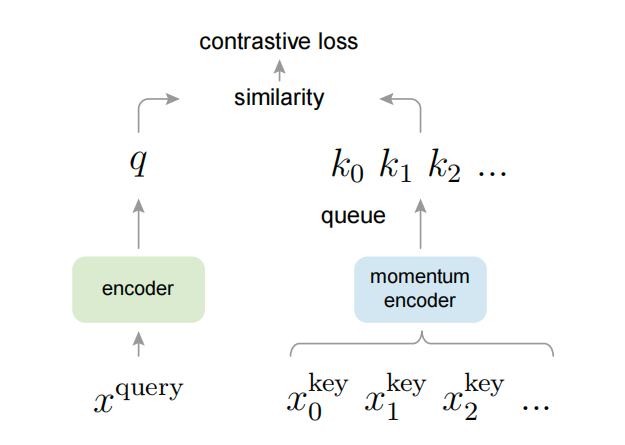
从构建动态字典的角度,有两个关键点:1. 字典要大 2. 字典内的表征要一致
图1.的架构展示了如何计算对比损失,作者的主要改进是提出了queue和momentum encoder;
- 因为字典更大的时候,意味着需要更多图片,内存不够用,于是作者使用队列这个结构,mini-batch先进先出;
- 但是如果使用队列,那么不同时刻进出的mini-batch使用的会是不同时刻的encoder,会导致不同mini-batch跟query对比的时候不在同一基准上;所以作者又提出了采用momentum这个结构,其中是当前时刻query的encoder参数,是当前时刻key的encoder参数
当动量m很大的时候,key的参数更新的很慢,可以近似认为不同mini-batch的encoder参数是一致的,因此保证了key的一致性;
基于queue和momentum encoder,保证可以构建又大又一致的字典
# InfoNCE Loss
query跟key越相似,损失越小;越不相似,损失越大,作者选取了InfoNCE Loss这个损失函数;如果像分类任务一样,使用-log softmax 做交叉熵损失函数,那么在对比学习中,这个数值会很大,因为对比学习中,每个跟query不同的都是一个类,这时候引入了NCE Loss,将很多分类简化成二分类,即数据和噪声(noise),每次拿数据和样本做对比(contrast),当正样本很少,负样本很多的时候,大家基本上都不是一个类,因此从全部数据中随机选一些K个负样本计算loss,将其看成一个多分类的问题,去估计(estimation);作者的infoNCE就是NCE基础上加了一个温度系数,来控制对不同样本的敏感程度,引入这个公式
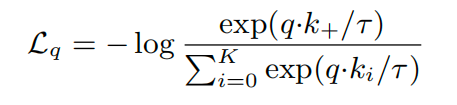
图2. InfoNCE loss
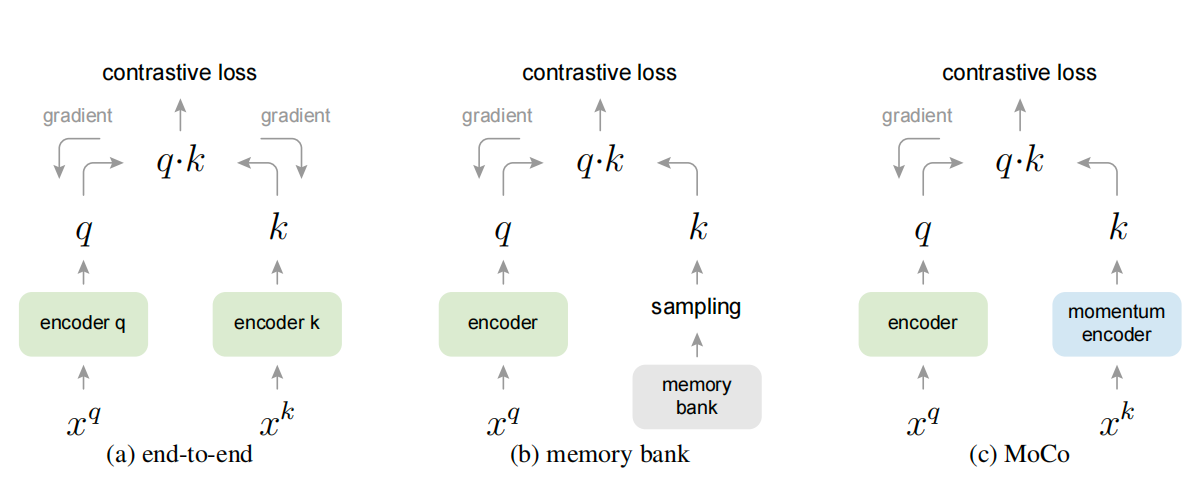
图3. 不同的学习方式
- 中的看上去很好,样本都是在一个batch里,过同样的encoder,所以样本高度一致了;但是缺点就是字典不能太大,因为内存有限。。(SimCLR中的方式end-to-end,因为google有tpu,可以无脑上大batch)
- 中的MemoryBank方式字典很大,但只有一个query的encoder,对于key,把整个数据集上的特征都存到一起,比如imagenet就有128w个样本x128特征,线下存储;但是牺牲一些一致性,因为encoder是一直在学习的,所以每次从memorybank中取样本算相似度的时候,encoder都已经更新了
- 中就是MoCo提出的,采用队列的方式,然后加Momentum

图4. 伪代码