# MAE:Masked Autoencoders Are Scalable Vision Learners
带掩码的自回归编码器是可扩展的视觉学习器
He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16000-16009.
- 前面vit采用了transformer的encoder架构用到cv中,核心是patch的切分以及大量标注数据的下游微调,精度比cnn会高;这篇文章MAE采用了无监督数据进行预训练,将ViT扩展至没有标号的数据上,即cv版的完形填空(vit主要是用大量有监督数据进行预训练,无监督的预训练做了很少效果不好;本文是大规模无监督数据上预训练;vit是输入整个图片,本文是encoder只输入非mask部分,并且少量的块为非mask)
- 训练的时候是用非对称的encoder-decoder结构,预测的时候只用encoder
- 作者考虑了到底是什么使得自编码的mask在nlp和cv效果不同,三个原因
图1. MAE架构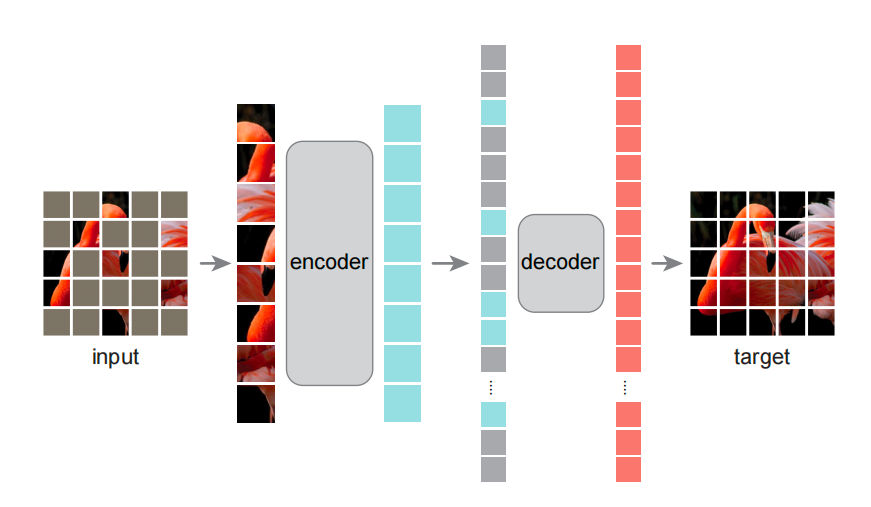

图2. MAE效果(大量mask,恢复图、原图)
# 几个实验结果
图3. 几个实验结果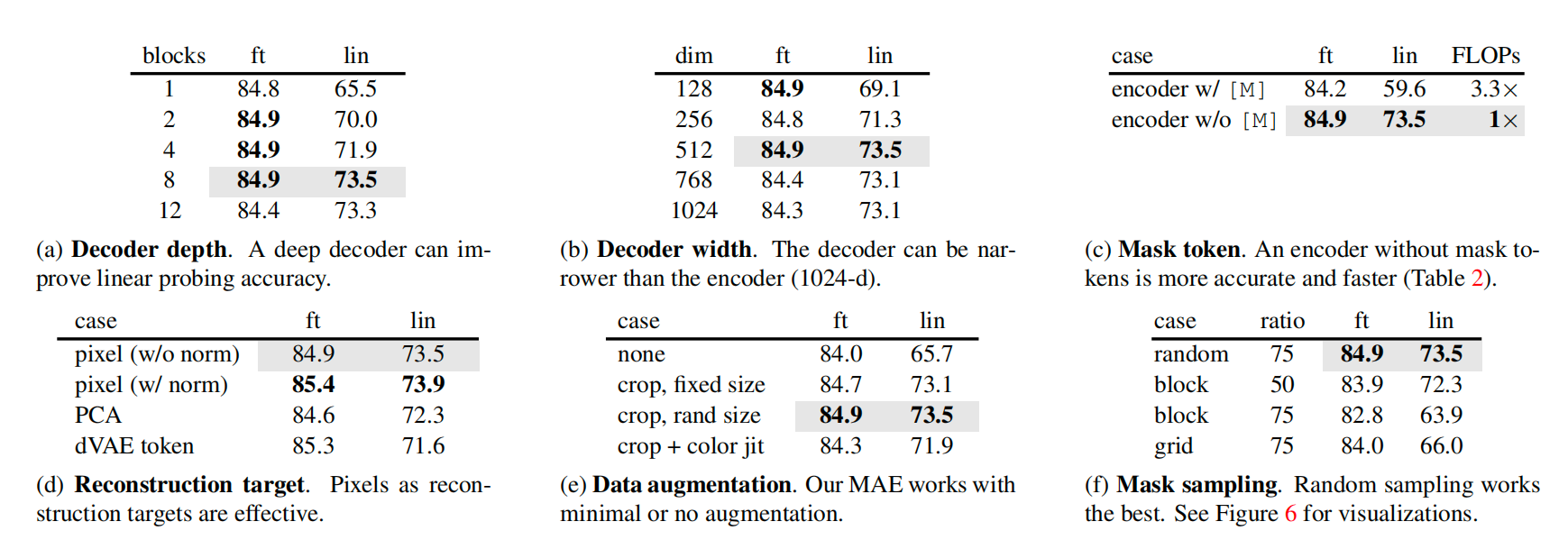
- end-to-end fine-tune时,不同block效果差不多;只训练最后线性分类层,block在8的时候最好
- decoder width 512效果最好
- encoder不加mask的patch时,效果更好,而且计算量少
- 重构的时候不同目标,复原pixel掩码部分,复原pixel掩码部分(每个pixel做归一化),PCA、dVAE token
- 按随机大小裁剪效果就很好,对数据增强不太敏感
- 最简单的随机采样效果最好
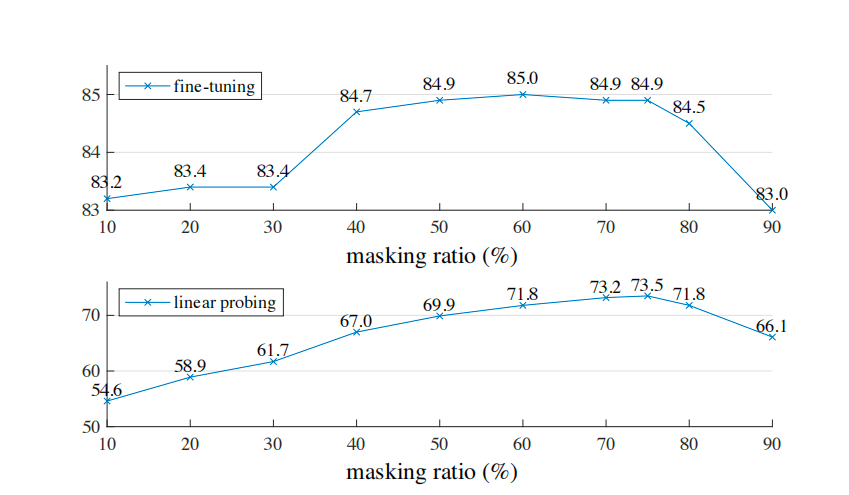
图4. 不同mask ratio的效果

图5. 不同mask方式