# ViT:An image is worth 16x16 words: Transformers for image recognition at scale
将Transformer应用到CV领域
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929
(2020).- 把Transformer用在cv领域想法很好,但是Bert中self-attention是两两单词做自注意力,因此复杂度是,bert中也是maxlen=512;一个想法是把2d的图片展开为1d的向量,但是图片的size常常是224x224=5w+,因此像素点很多,复杂度太高
- 因为复杂度高,没法全用attention,因此当时一些方法是conv和attention一起用;或者想办法降低序列长度,比如用特征图当作transformer的输入;或者改造attention,比如孤立attention机制,轴attention,但是虽然理论上有效,但是没法在训练上加速,所以效果也不好
- 作者受bert启发,不想修改其他架构,而是希望直接将transformer迁移过来,作者解决长度问题的方法是,将图片划分网格,每个网格是个patch=16x16,对于224相当于W=14、H=14,长度变为14x14=196,然后将每个patch过一个fc layer得到linear embedding,传给transformer,训练方式是有监督的(之前也有相似的做法,只不过没有扩展大数据和size)
- 作者在中等数据集比如imagenet上测试,发现如果不加约束,跟resnet效果也差不多,因为transformer跟conv相比,缺少一些归纳偏置,因此需要更大的数据才能学到这些知识,所以作者在更大数据集上训练,果然效果很好
- 作者也加了归纳偏置,比如抽图像块的时候位置编码,除此之外就没有任何图像特有的偏置,然后直接用标准transformer
# Model
在原型设计上,尽可能保持Transformer不变
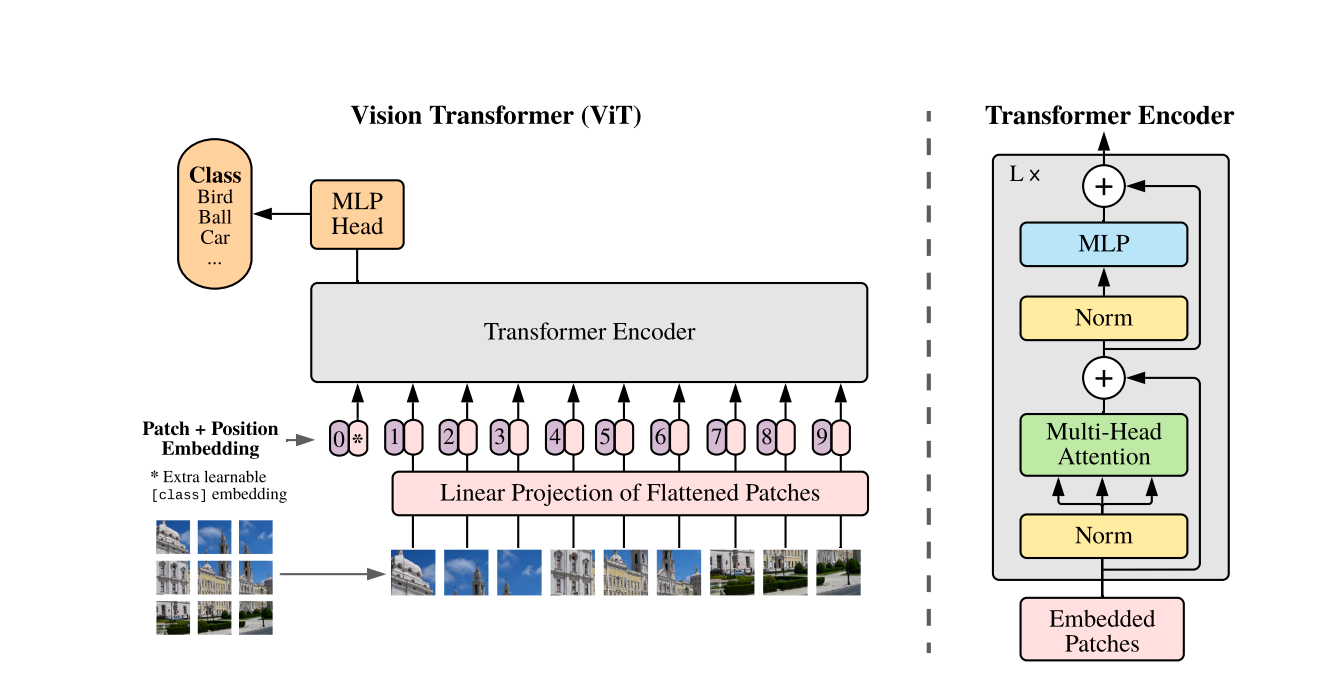
图1. Vit模型架构
# Input
一张图片224x224,做16x16的patch,因此总的token数为,也就是196;每个token为16x16x3的patch,因此每个patch有天然的768d的embedding,然后过一个768x768的全连接层,就可以转换成196x768d的向量了,一共196个token,每个token为768d的向量;最终还要加一个[CLS],因此一共是196+1=197个token,维度768;然后加上位置编码信息,最后就是197x768的tensor
# FFN
197x768投射4倍=3012,然后再投射回去768,最终输出
# Finetune
在高分辨率图片上微调,理论上效果会更好,但是预训练的Transformer不太容易调整尺寸,如果用大分辨率图像,但是patch还是16,那么序列token长度明显会增加,因此transformer理论上是可以处理任意长度的,但是提前预训练好的位置编码就不能用了,因为序列长度变了,这里作者用了一个2d的插值,这里的插值也不是无限插,插值可能会掉点,只能是个临时解决方案,也是finetune的一个局限性
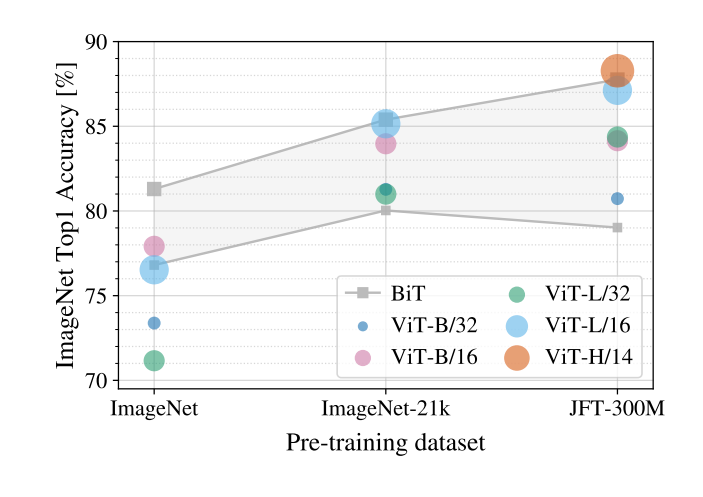
图2. 不同规模数据集预训练,然后finetune的效果
# 其他
做了一些消融实验:
- 前面加[CLS]进行最终分类或者直接最终的embedding进行Global everage pooling做分类,效果基本相同
- 不加位置编码的差一点
- 1d位置编码和2d位置编码基本相同
- 2d绝对位置编码和相对位置编码也差不多