# 决策树应用(sklearn)
# 问题说明
对于一个人是否购买电子产品,有age、income、student、credit_rating几个影响因素,根据这些影响因素拟合出一棵决策树,并进行预测。
| RID | age | income | student | credit_rating | class_buys_computer |
|---|---|---|---|---|---|
| 1 | youth | high | no | fair | no |
| 2 | youth | high | no | excellent | no |
| 3 | middle_aged | high | no | fair | yes |
| 4 | senior | medium | no | fair | yes |
| 5 | senior | low | yes | fair | yes |
| 6 | senior | low | yes | excellent | no |
| 7 | middle_aged | low | yes | excellent | yes |
| 8 | youth | medium | no | fair | no |
| 9 | youth | low | yes | fair | yes |
| 10 | senior | medium | yes | fair | yes |
| 11 | youth | medium | yes | excellent | yes |
| 12 | middle_aged | medium | no | excellent | yes |
| 13 | middle_aged | high | yes | fair | yes |
| 14 | senior | medium | no | excellent | no |
# PythonCode
# 导入sklearn相关库
import sklearn
import csv
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
# 导入csv文件,读取原始数据
file = open(r'/Users/lianyongxing/Desktop/machineLearning/decisionTree/src/AllElectronics.csv','rt')
reader = csv.reader(file) #按行读取
headers = next(reader)
featureList = []
labelList = []
for row in reader:
labelList.append(row[-1])
rowDict = {}
for i in range(1, len(headers) - 1):
rowDict[headers[i]] = row[i]
# 数据格式转化
# 字典的向量化
# 这个过程将原始数据中的属性值youth、high、no等数据转化为sklearn可识别的0、1;将原始数据中的标签yes、no转化为sklearn可识别的0、1
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
# # print(dummyX)
#
dummyY = preprocessing.label_binarize(labelList,classes=['no','yes'])
# # print(dummyY)
# 构造决策树
# 根据数据构造决策树
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
# 输出结果
# 将输出的结果保存为dot文件,后续用graphviz程序打开
with open("output.dot",'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file= f)
# 可视化
# 在终端中将dot文件转换为可视化的pdf文件
dot -T pdf output.dot -o output.pdf
# 结果
得到的决策树如下所示
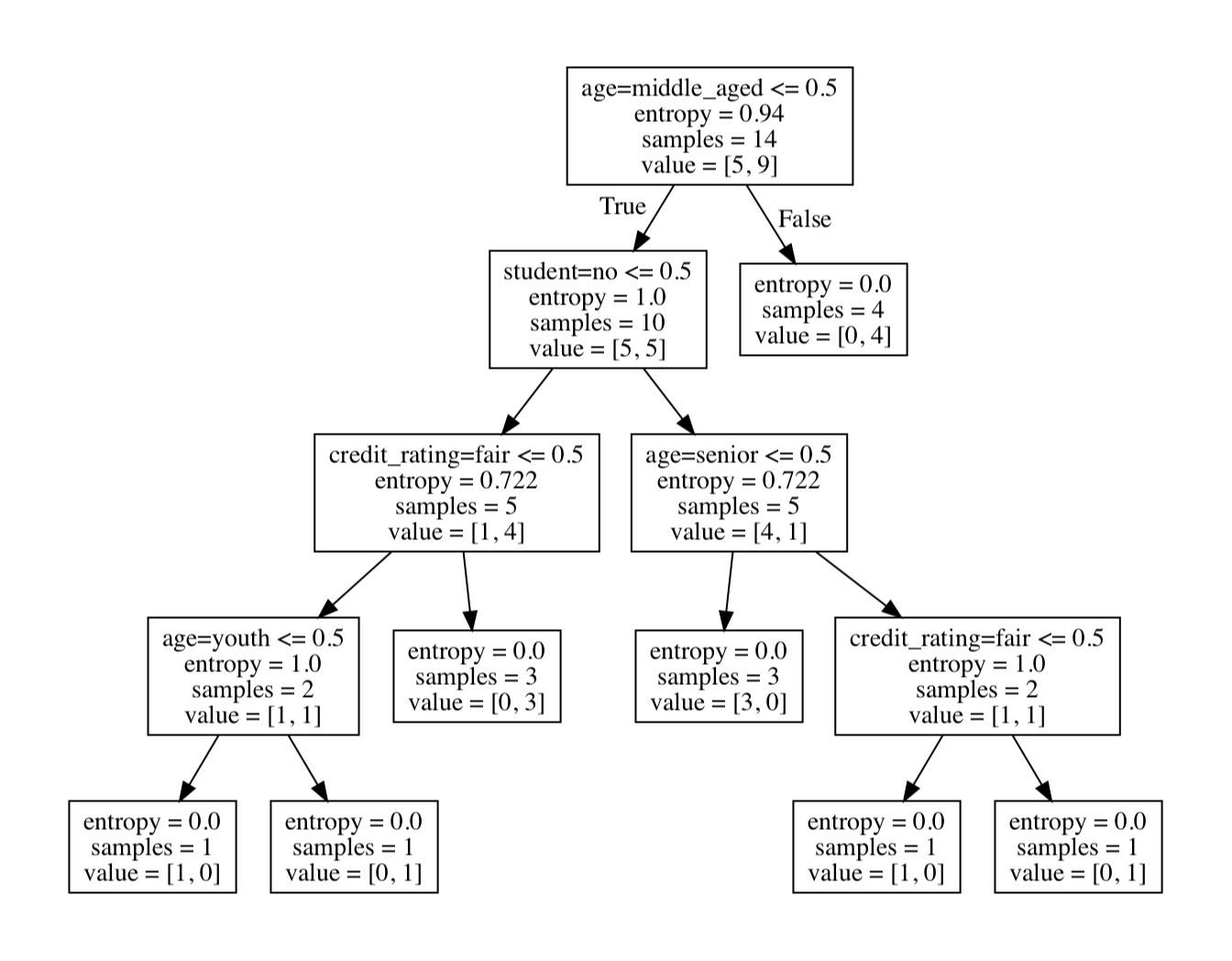
从中可以直观看出每一层的熵值和分类情况
# 预测
之后根据拟合好的决策树对新数据进行预测
# 在这里取了原始数据的第一行,然后把第一列和低4列的值修改了一下,作为新的输入
# 然后用决策树进行预测,得到predictY
oneRowX = dummyX[0, :]
print("oneRowX:" + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[3] = 0
predictedY = clf.predict([newRowX])