# CNN
# 原理
卷积神经网络
CNN的结构跟传统NN不一样,输入的是一个二维的神经元(28*28)

在输入的二维神经元中,选出一个小方块和下一个神经元进行连接。
比如最开始输入是28*28的网络,如果用一个5*5的小方块进行卷积,最后输出的大小是24*24
每次小方块移动多少,定义为。在卷积神经网络中,所有的神经元使用的是共享权重和偏向。
此时的更新公式为
上式中,假设。
对于第一个隐藏层,所有的神经元探测到同样的特征,只是根据不同的位置(当小方块在哪个位置,探测的就是哪个位置的特征)。这样处理使得图像仍然保留二维的信息,保留了图像原始的形状特征。
# Feature Map
从输入层到转化层,可以用不同的feature map(小方块),从而可以得到不同的输出结果,如下图所示。

对于,大致可以这么理解:
对于一个图,大小为10000*10000,如果按照传统的算法(假设隐藏层30个神经元),一共需要10000*10000*30个参数,这个数据量太大了,于是采用一个小方块(假设大小是5*5)共享权重,这样输入层到第一层每个神经元就只需要25(权重)+1(偏向)个参数,一共26*30个参数。这样虽然能节省参数,但是这一个小方块只是提取了图像的一种特征。实际上,我们需要提取多种特征,于是就多做几个不同的小方块,每个小方块提取一种不同的特征,这样就可以得到原始图像在不同特征下的输出。这些小方块就是不同的。
通常一些表现较好的方法都是使用更多的。
# Pooling Layers
用来浓缩神经网络的输出,减小尺寸

对于操作后的图像,可以进行最大值池化,即取一小块中的最大值作为这一小块的代表,这种方式可以压缩图像。
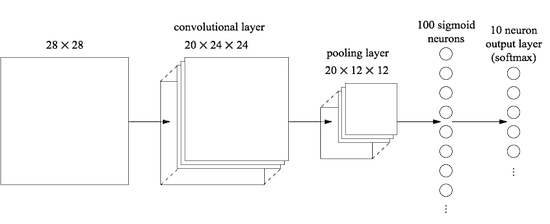
对于整个CNN的过程,可以简单得表现为下图所示(在最后使用了基本神经网络的全连接)
# 防止overfitting
CNN本身的层对于有防止作用,因为共享权重造成强制对于整个图像进行学习。
# 优点
- 大大减小了参数数量
- 本身防止(如果后面有全连接,也需要加入)
- 代替,避免不同层学习率差距大的问题
- 运算更快,每次更新少,但是可以训练多次
目前深度神经网络最多20层左右。